Focuses on using similarity and proximity to organize dense information in data visualizations without relying on explicit borders or dividers.
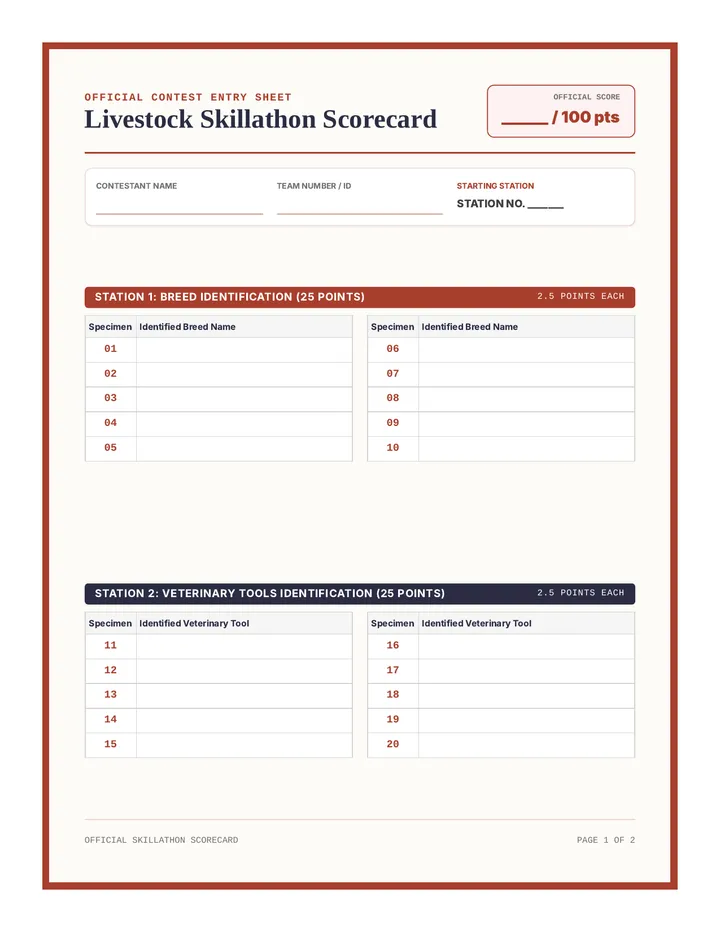
An immersive preparation program that equips agriculture students with the hands-on identification and evaluation skills needed to conquer competitive Livestock Skillathon contests.
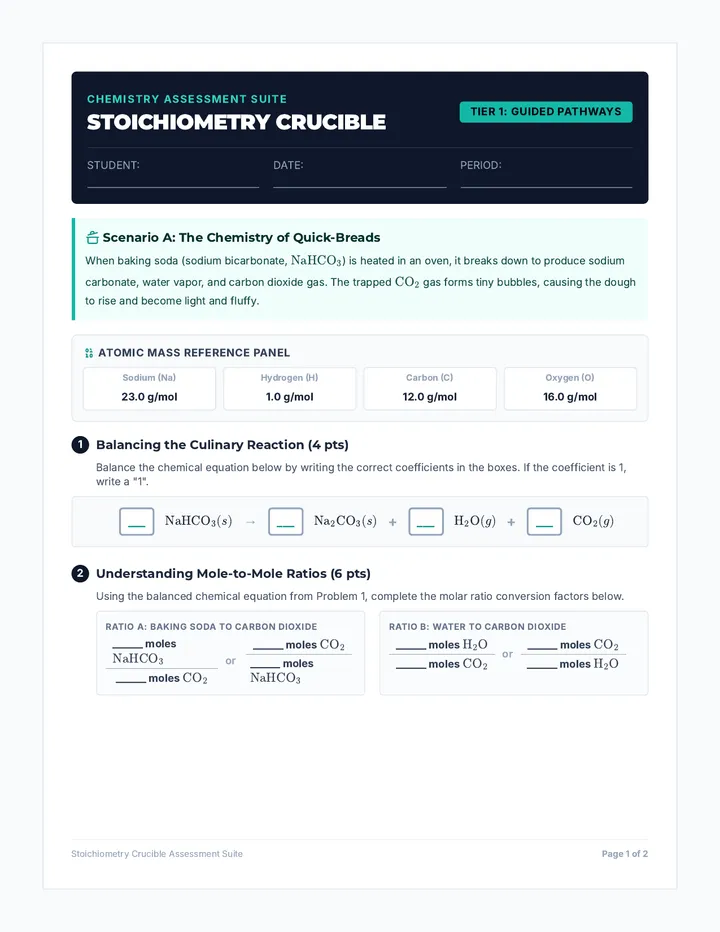
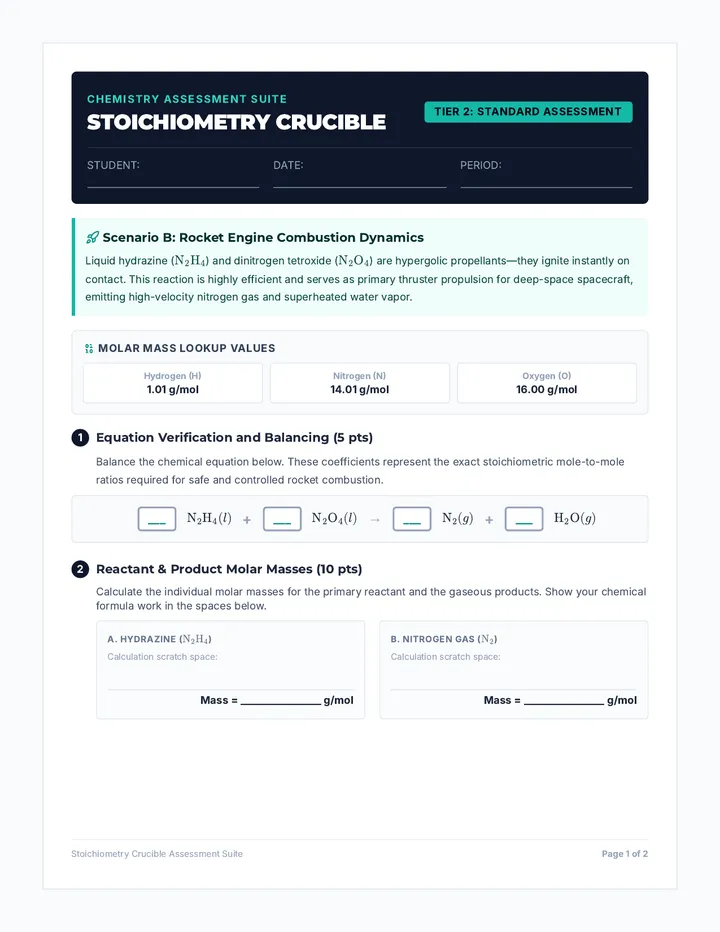
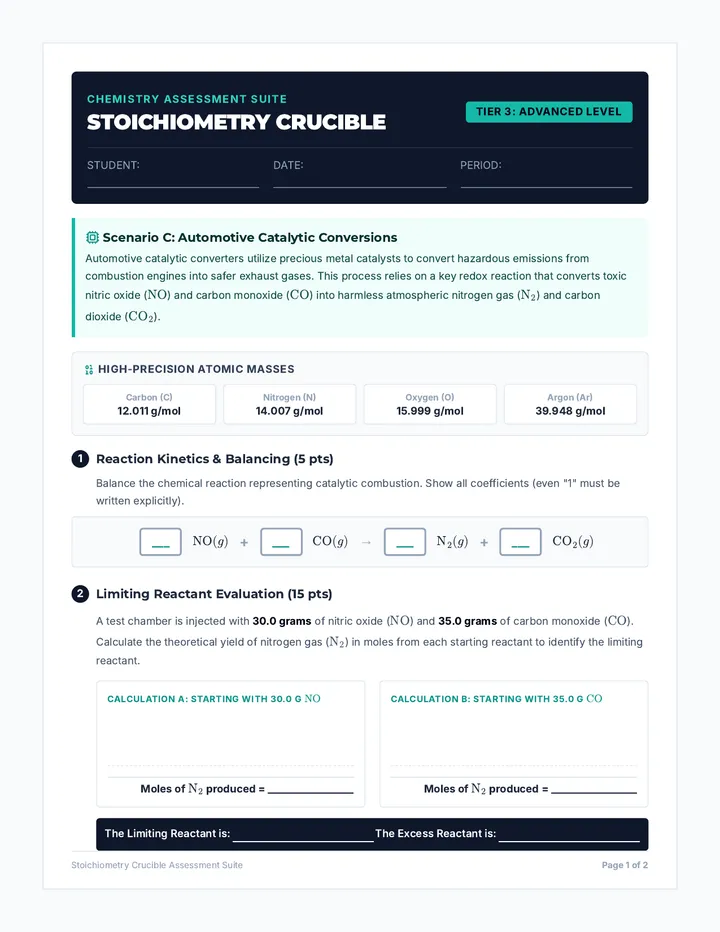
A differentiated stoichiometry assessment suite tiered by mathematical complexity, visual scaffolding, and conceptual depth. Features three distinct, parallel versions of a 2-page quiz centered around unique real-world chemistry applications.
Tier 3 (Advanced) Stoichiometry Quiz focusing on green chemistry & automotive emissions (catalytic converters), featuring complex limiting reactant analyses, theoretical yield, and atom economy calculations.
A comprehensive sequence focused on mastering business presentation skills and understanding company valuation for a professional audience.
A comprehensive study and practice package for Chemistry 1406 Exam 2. It contains a highly structured, side-by-side strategy guide paired with a 30-question practice exam, and a matching detailed answer key with step-by-step rationales.
Tier 2 (Standard) Stoichiometry Quiz focusing on aerospace propulsion (hydrazine rocket propellant combustion) with intermediate scaffolding, theoretical yield calculations, and percent yield analysis.
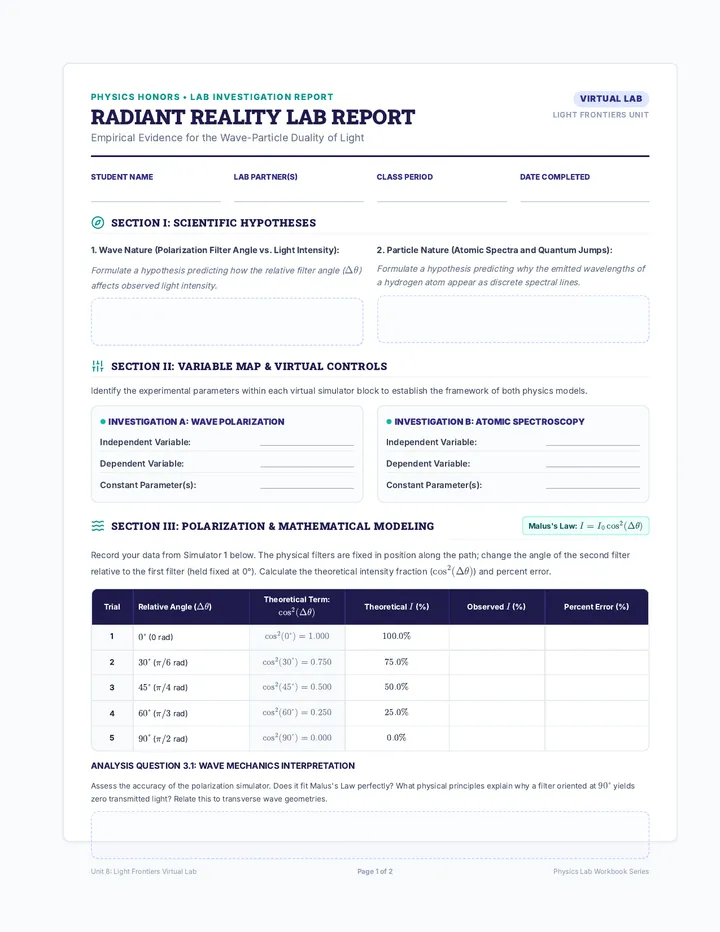
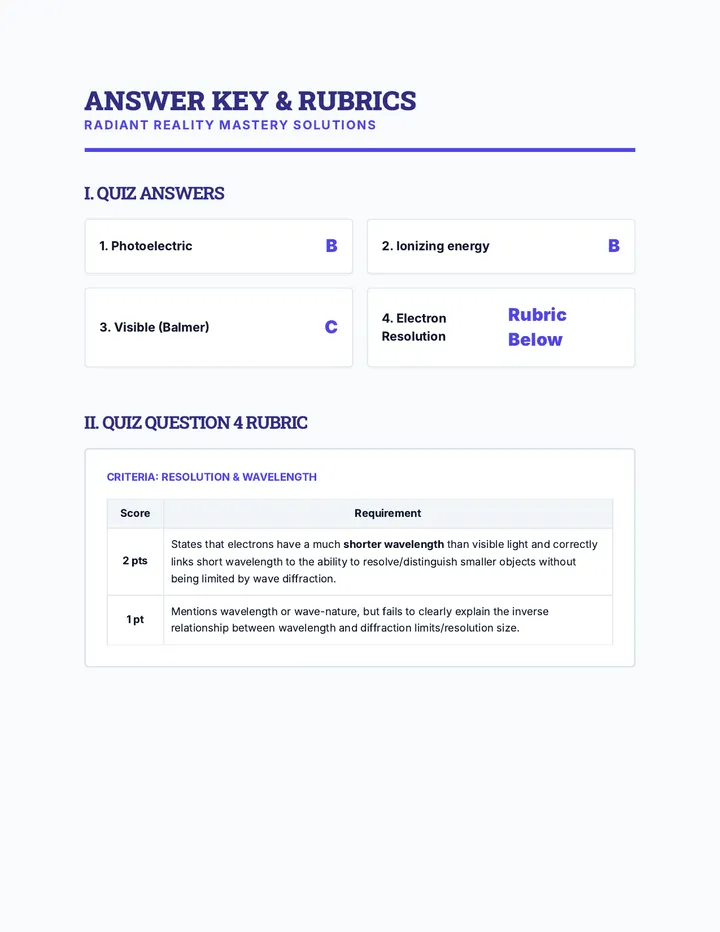
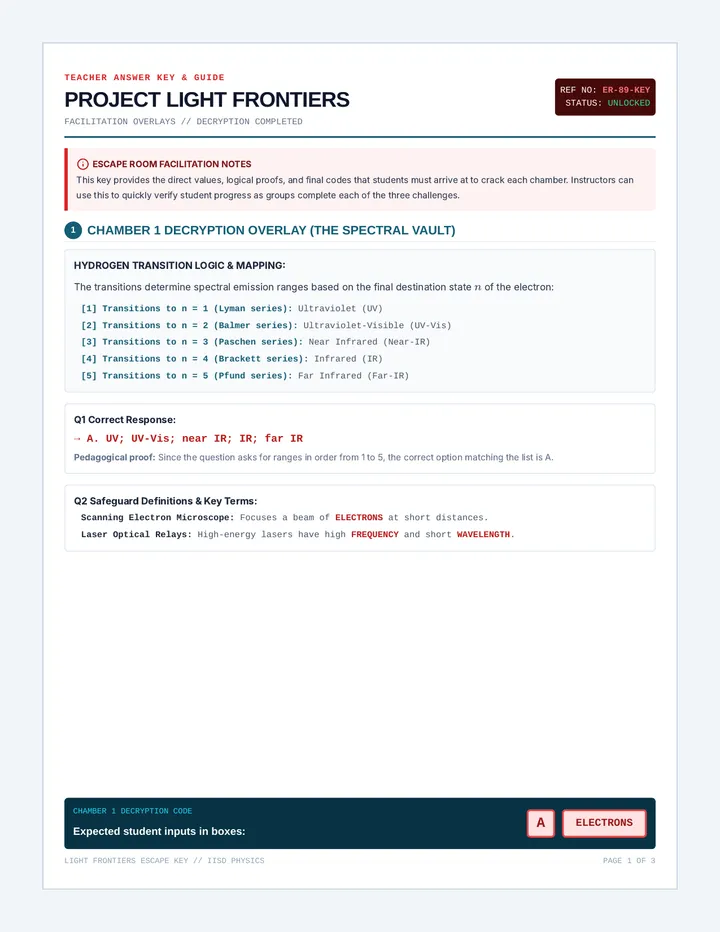
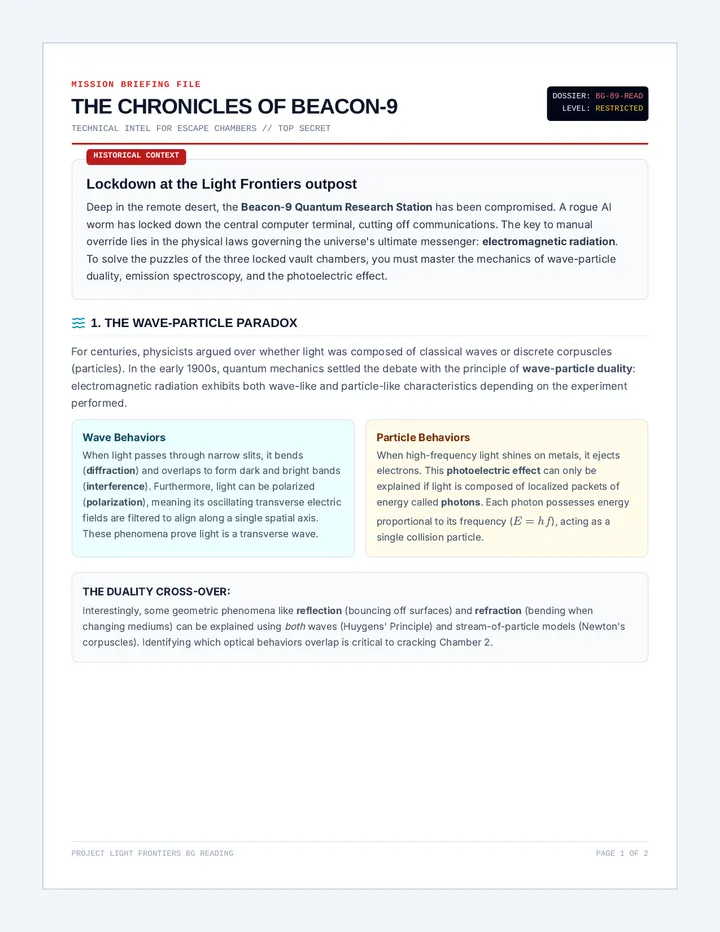
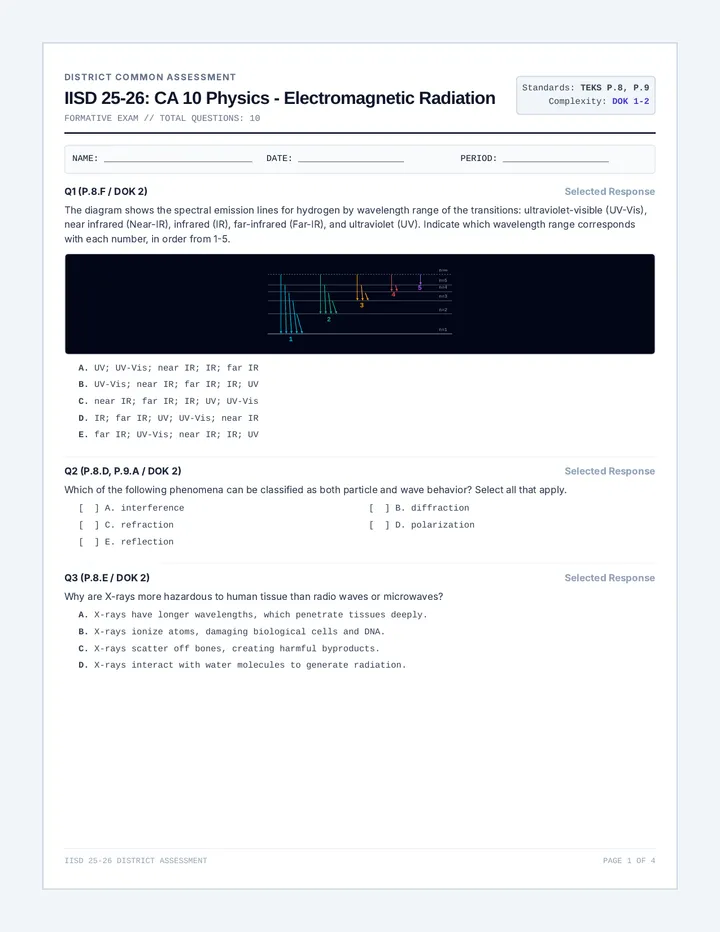
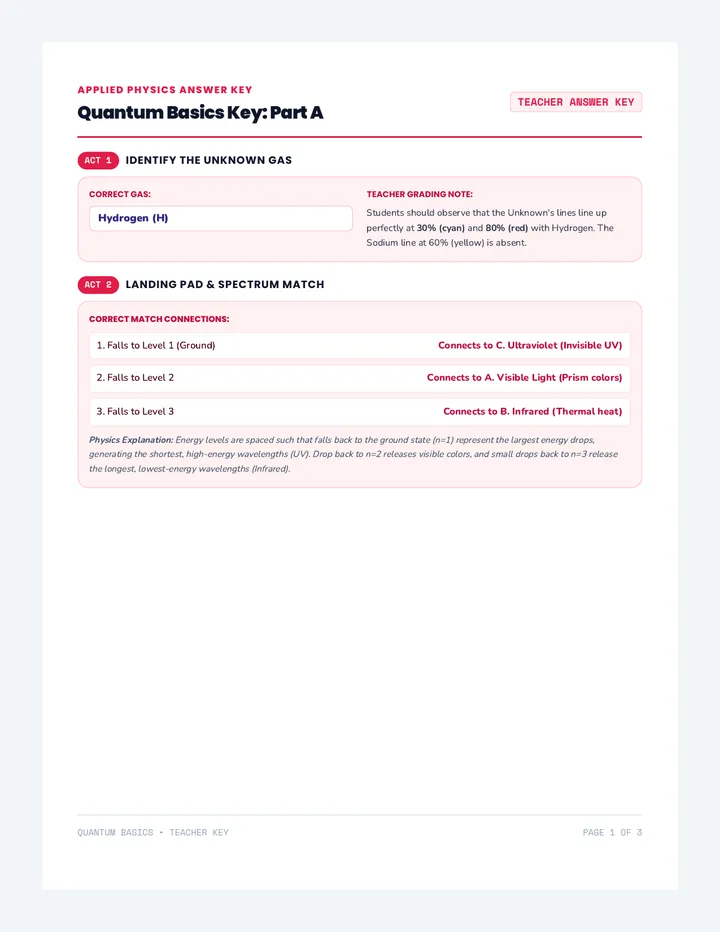
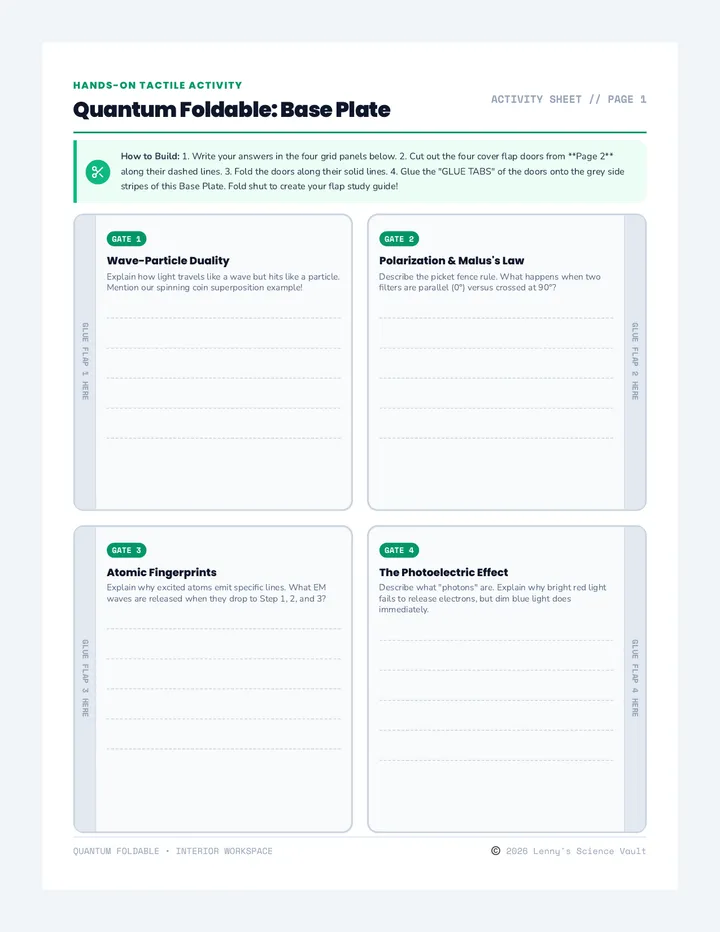
A comprehensive physics sequence exploring the dual nature of light, the electromagnetic spectrum, and the interactions of radiation with matter, including the photoelectric effect and polarization.
Students participate in a high-stakes, realistic mock Livestock Skillathon, rotating through four hands-on stations to test their knowledge and earn points.
Tier 1 (Scaffolded) Stoichiometry Quiz focusing on culinary chemistry (baking soda decomposition) with visual roadmaps, pre-structured dimensional analysis grids, and atomic mass reference cards.
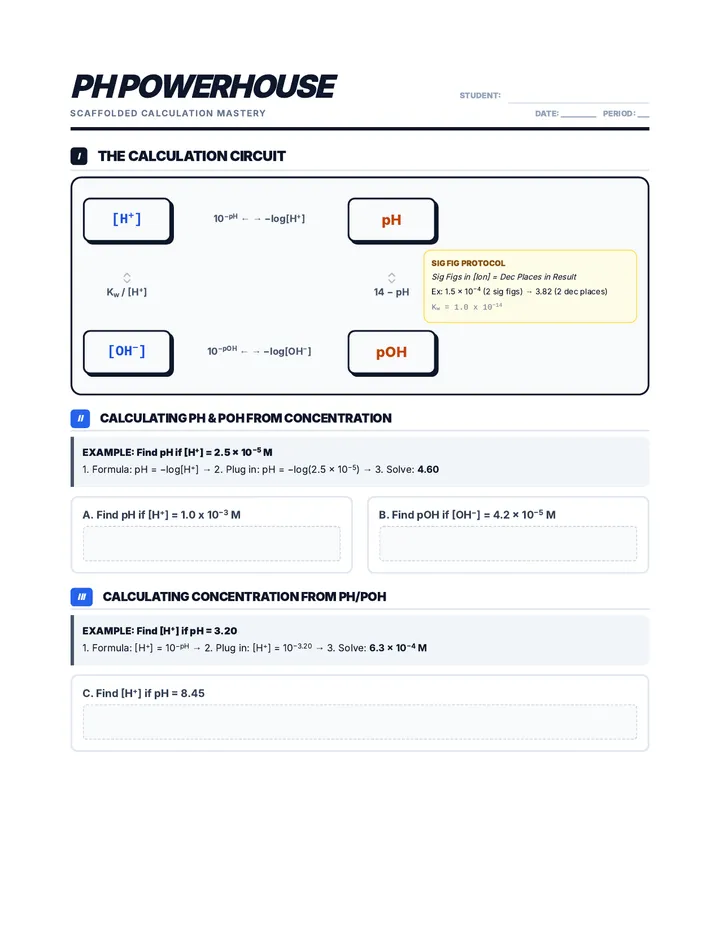
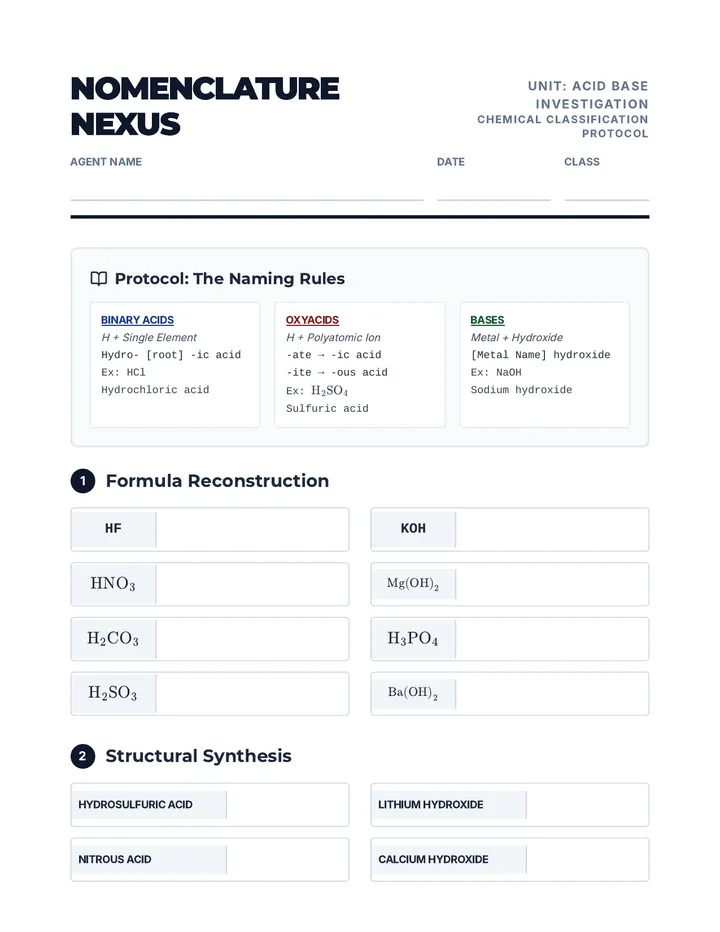
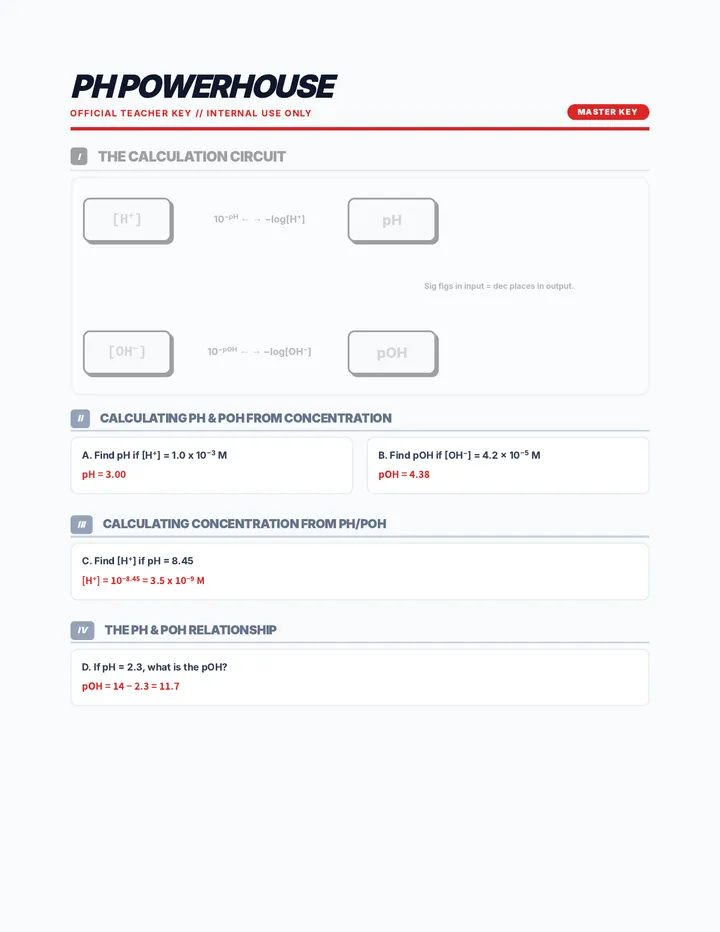
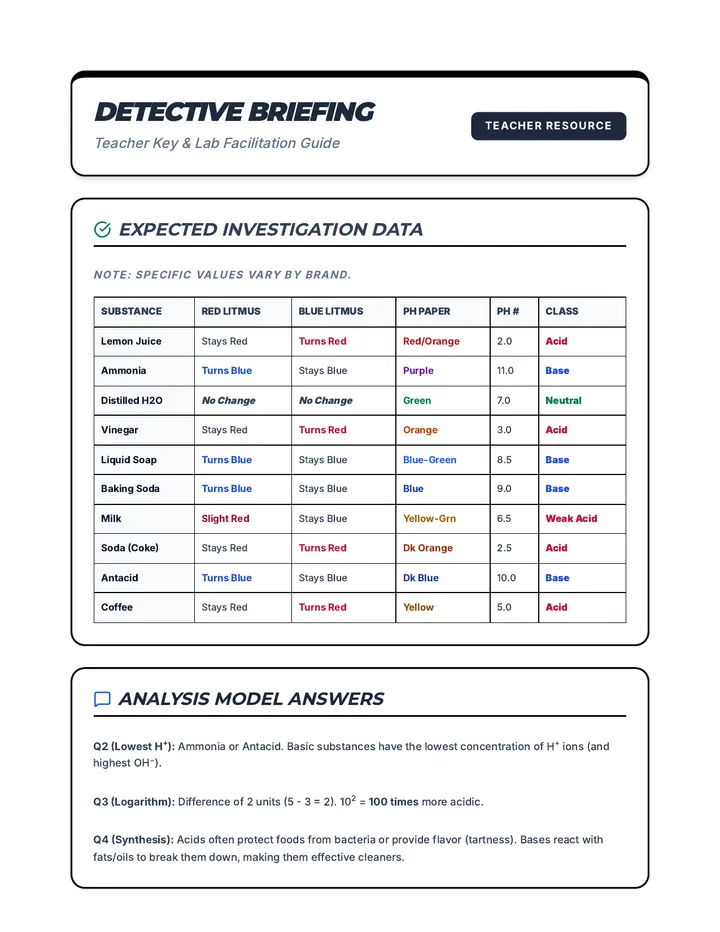
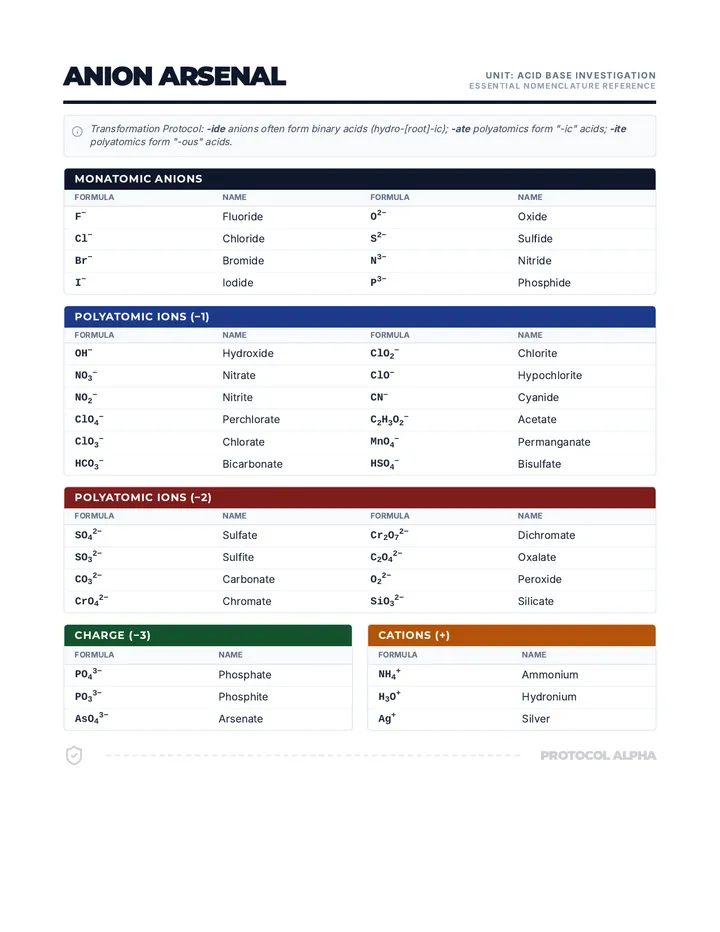
A comprehensive unit exploring the properties, reactions, and mathematical relationships of acids and bases, featuring pH calculations, titrations, and buffer systems.
Students learn to identify common feed ingredients and forages, and practice identifying retail cuts of beef, pork, and lamb by wholesale origin and cooking style.
A matching 7-page detailed answer key with step-by-step explanatory rationales for all 30 practice exam questions. Highlights correct option letters and breaks down calculations, stoichiometry mole-ratios, balanced chemical equations, and solubility rules for easy self-study or teacher facilitation with enlarged, highly readable black typography.