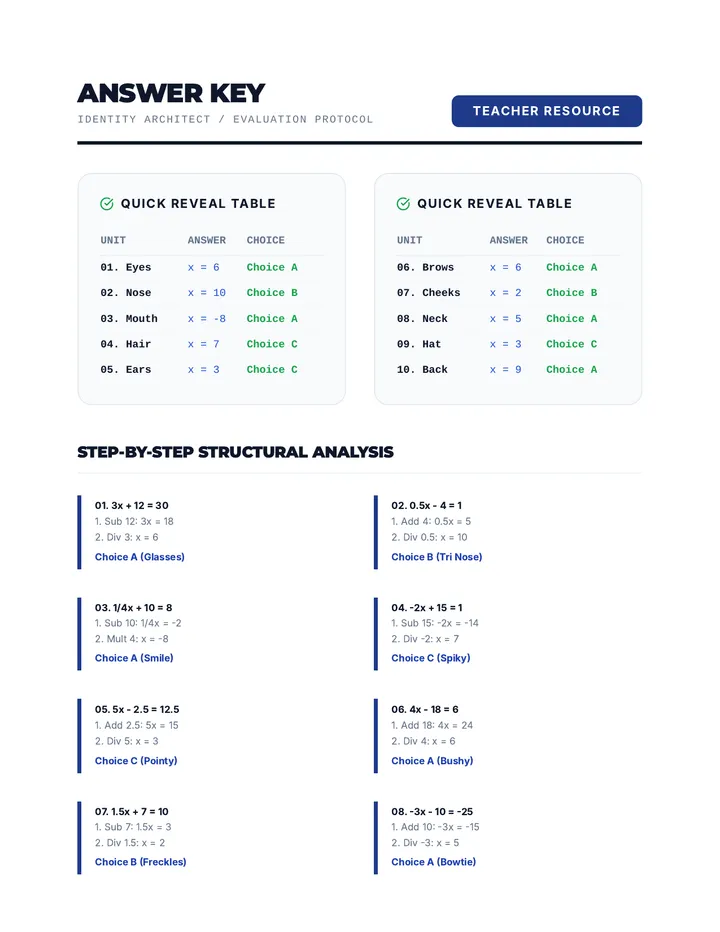
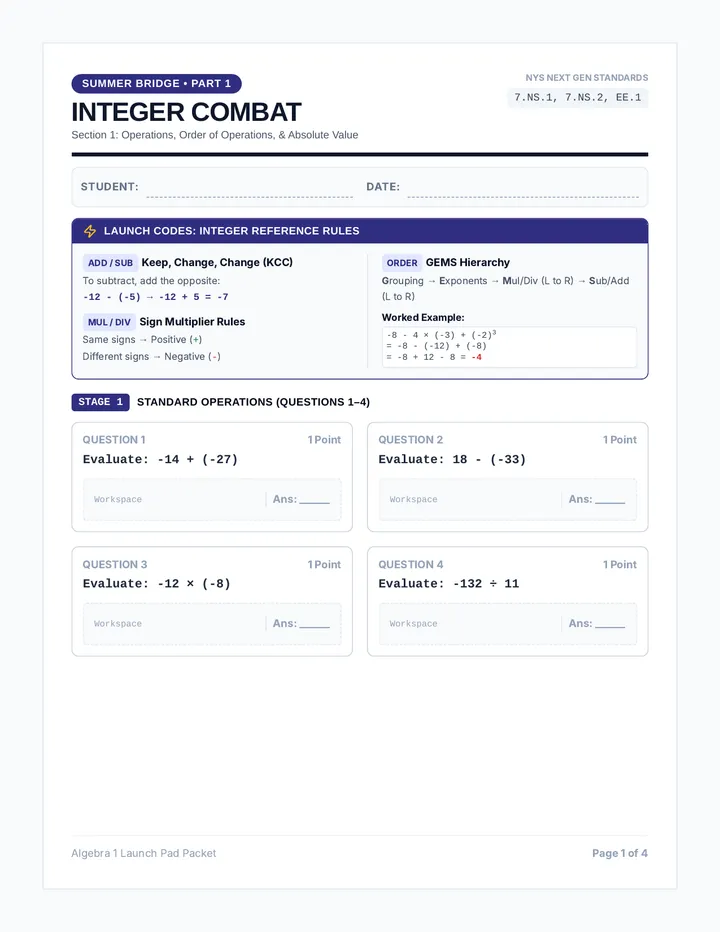
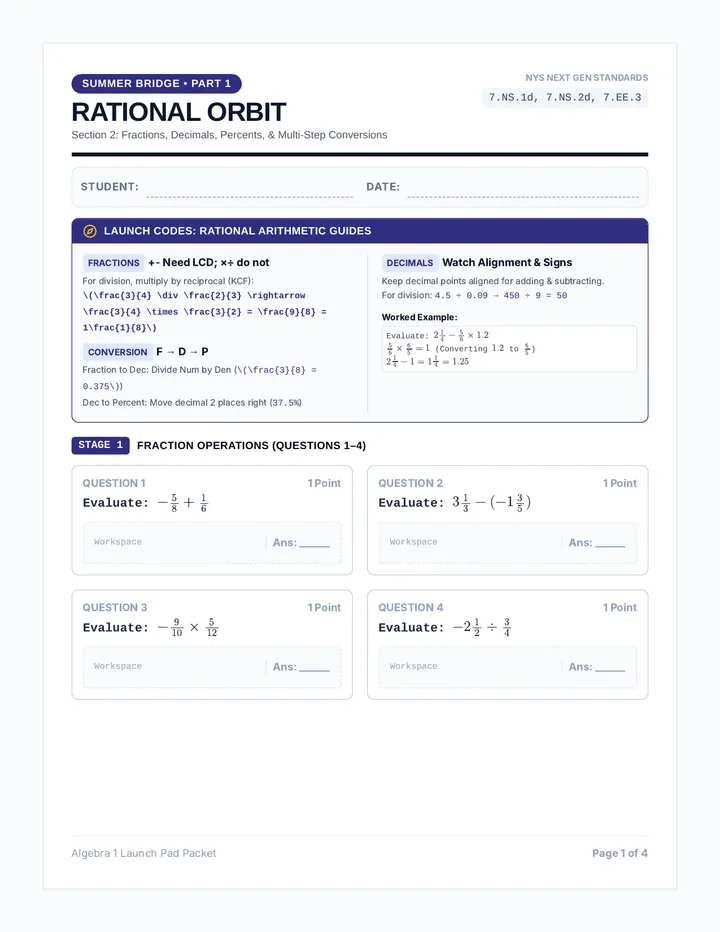
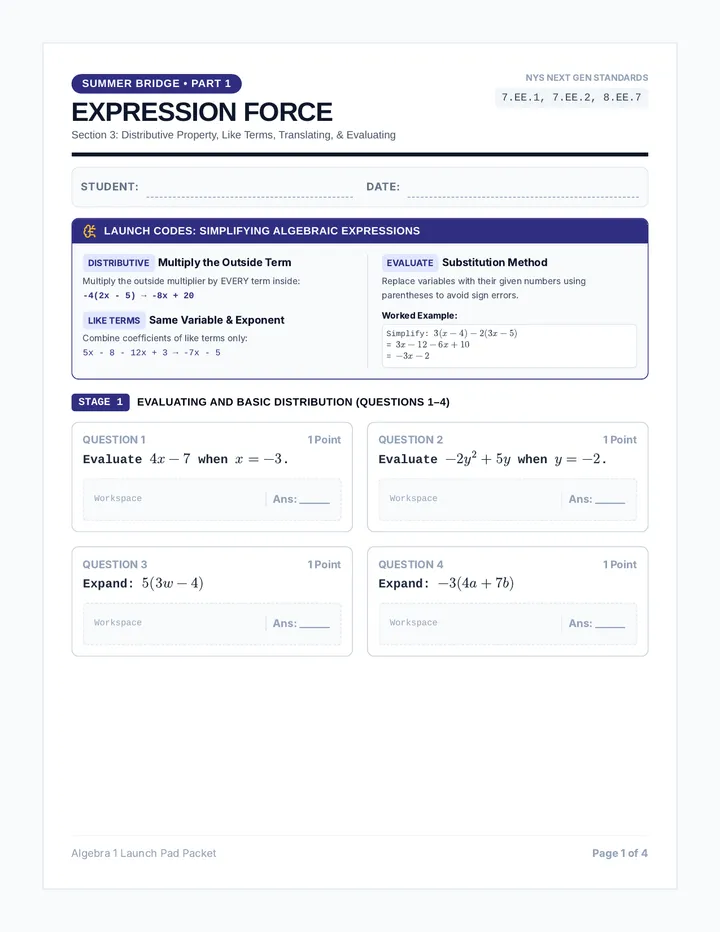
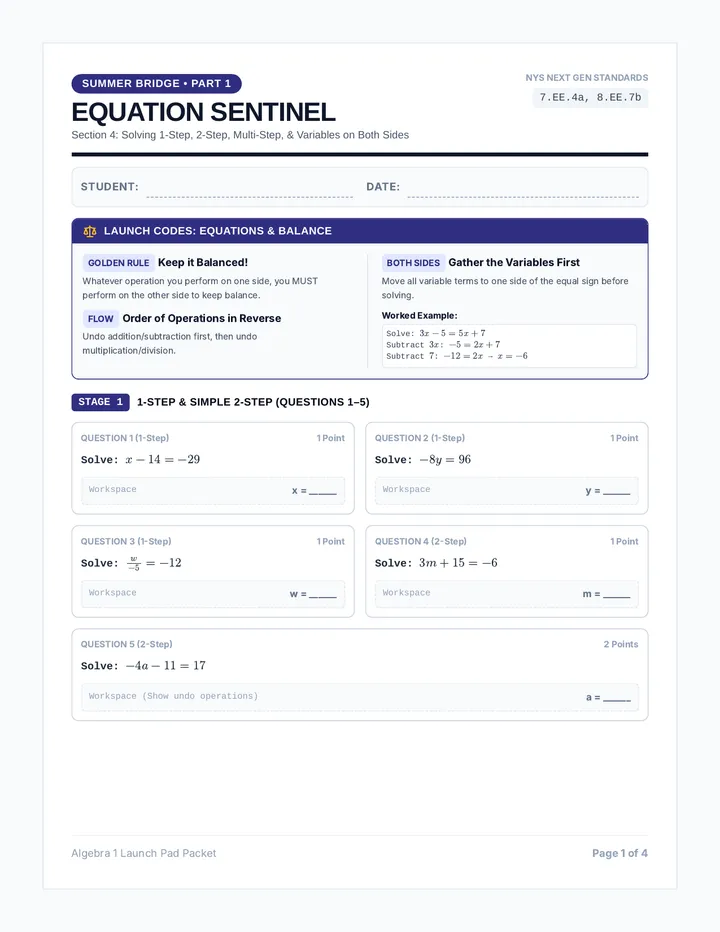
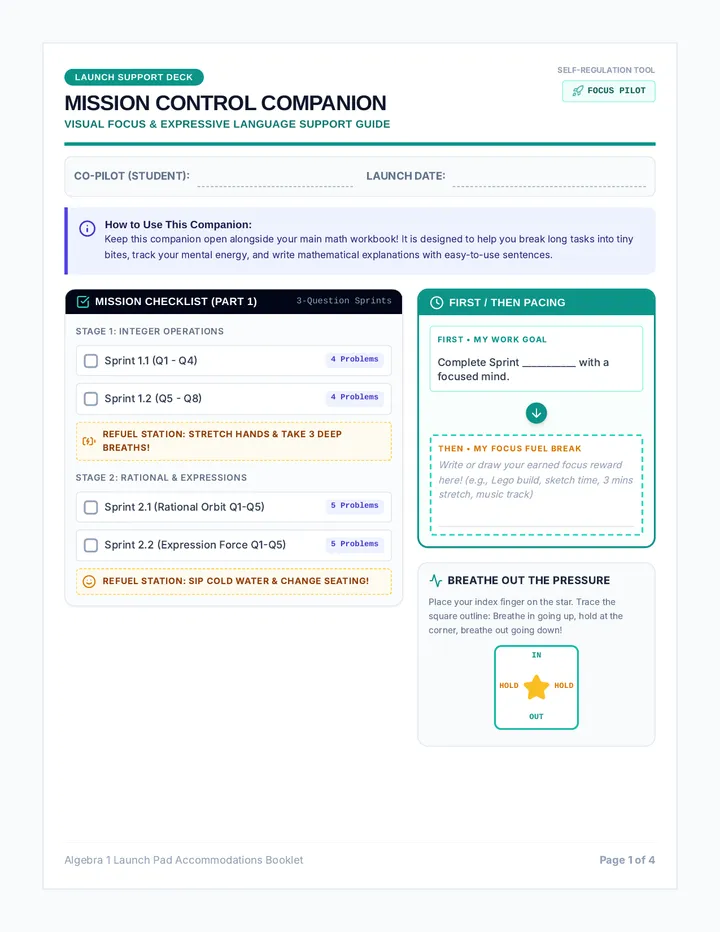
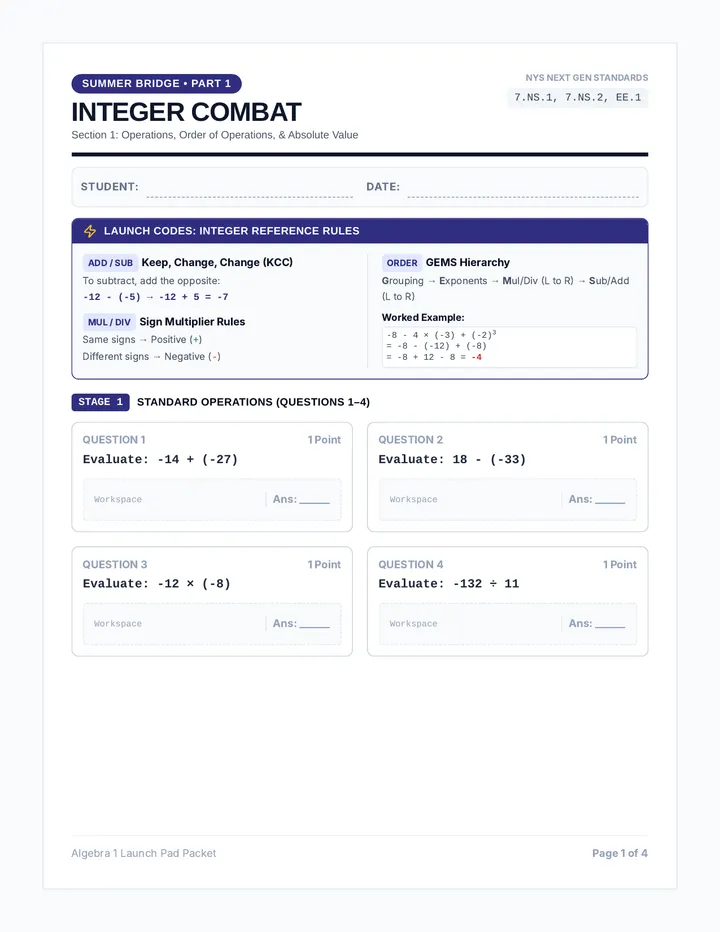
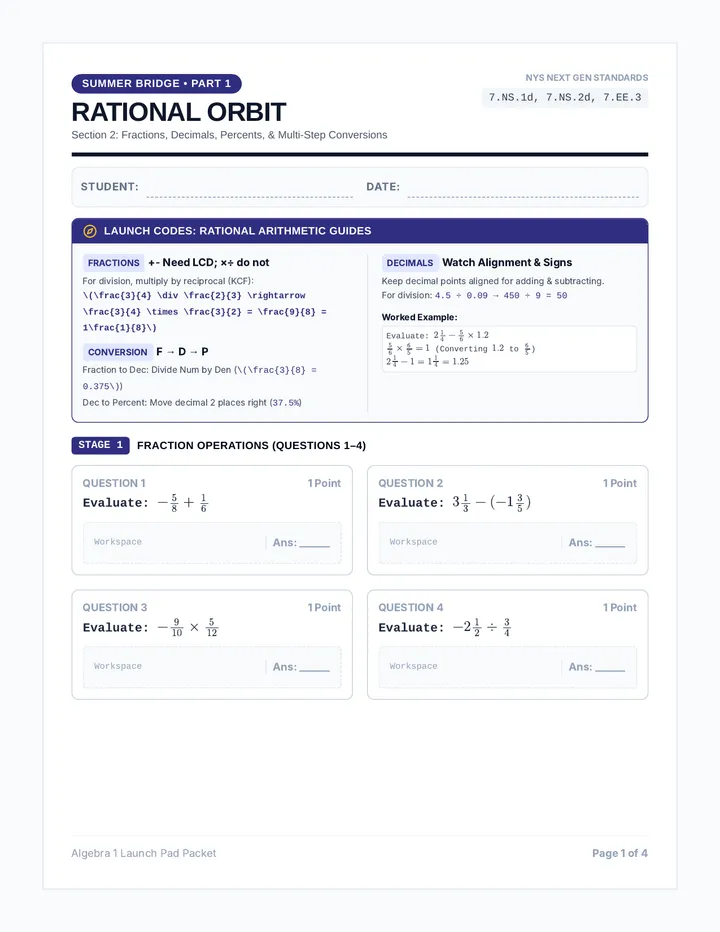
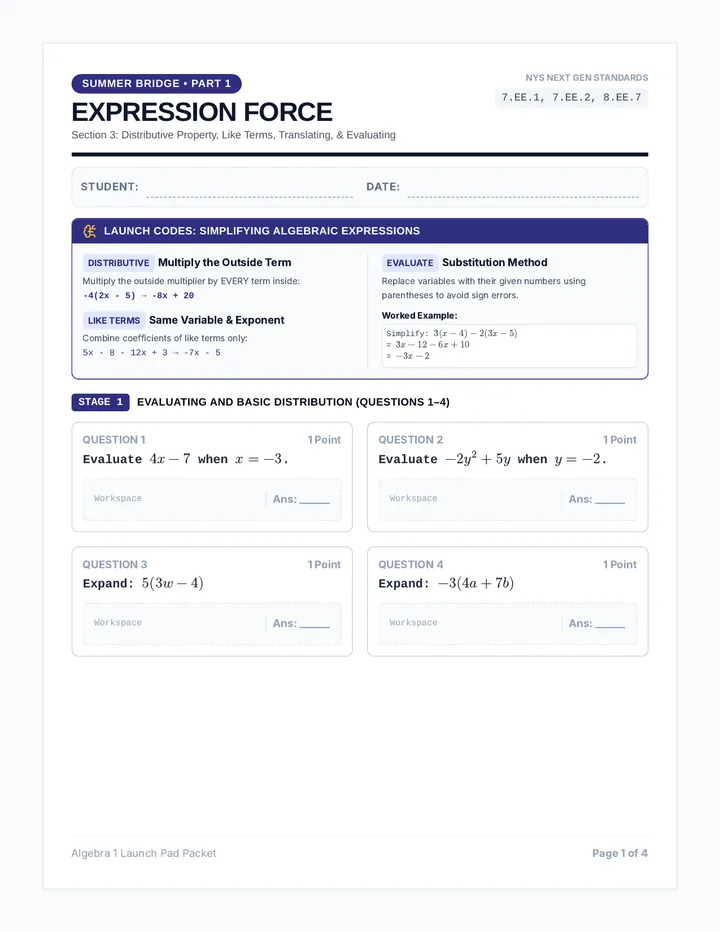
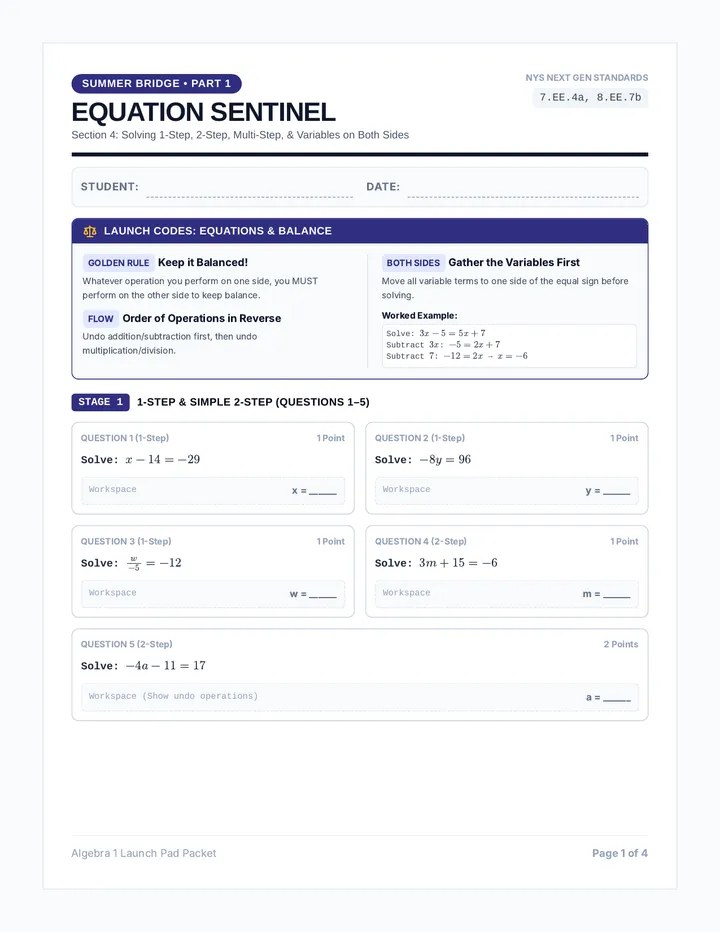
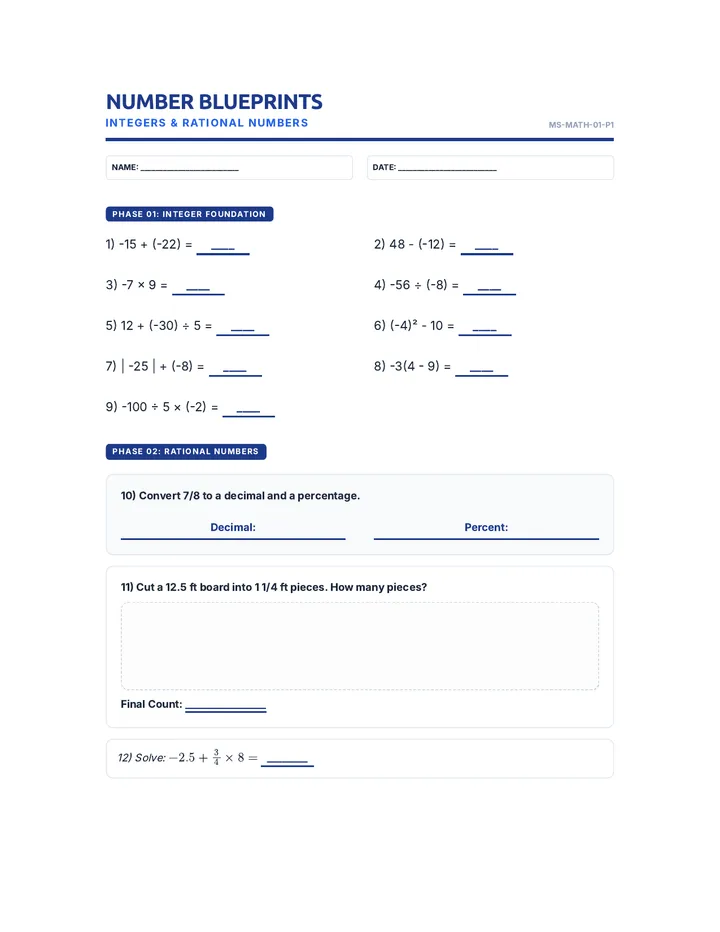
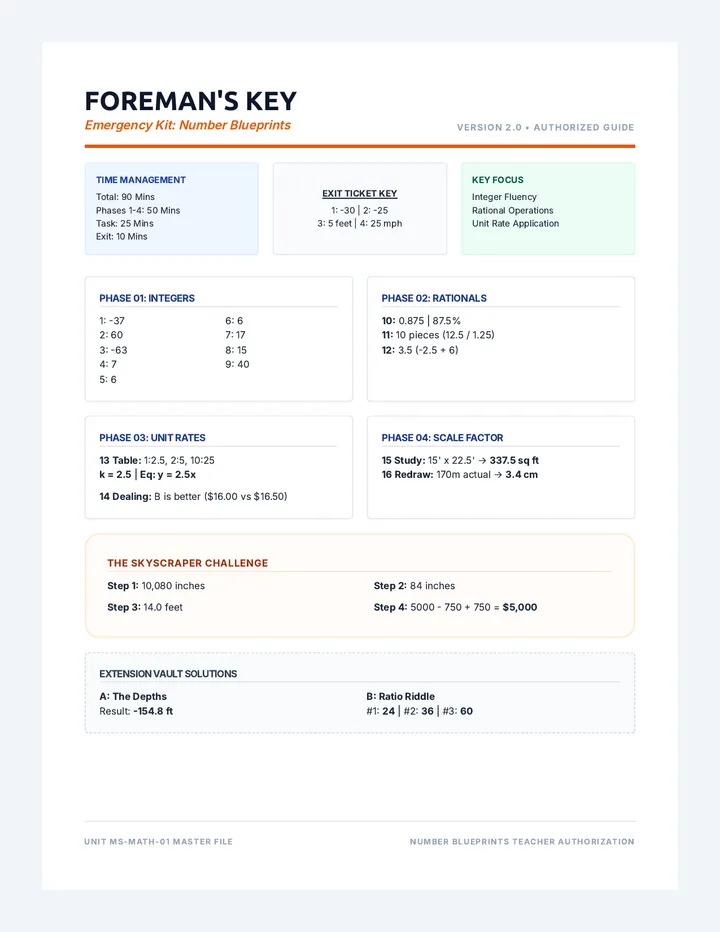
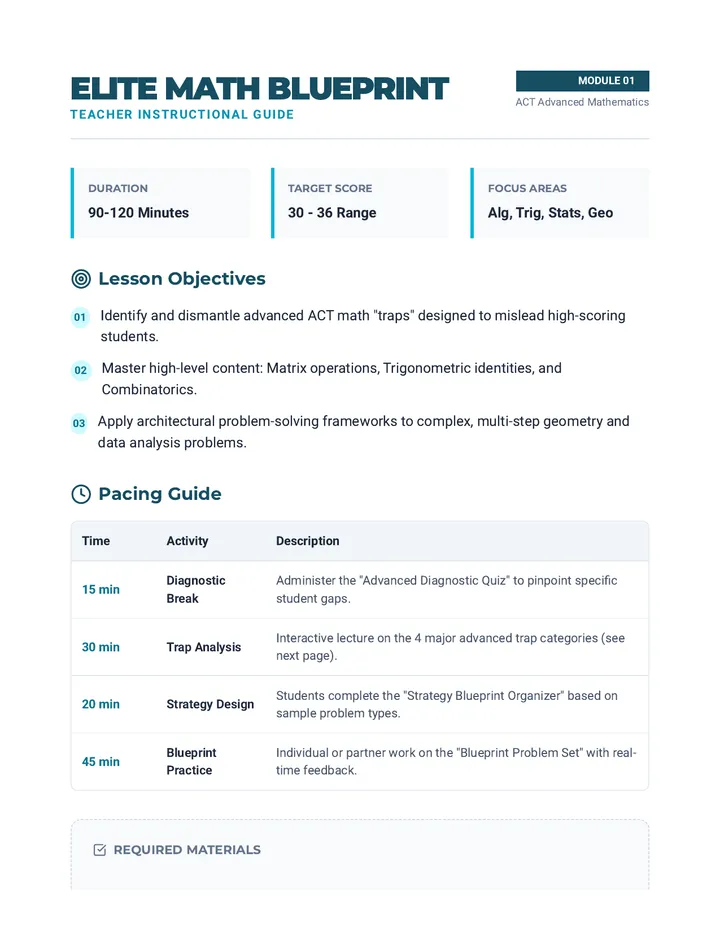
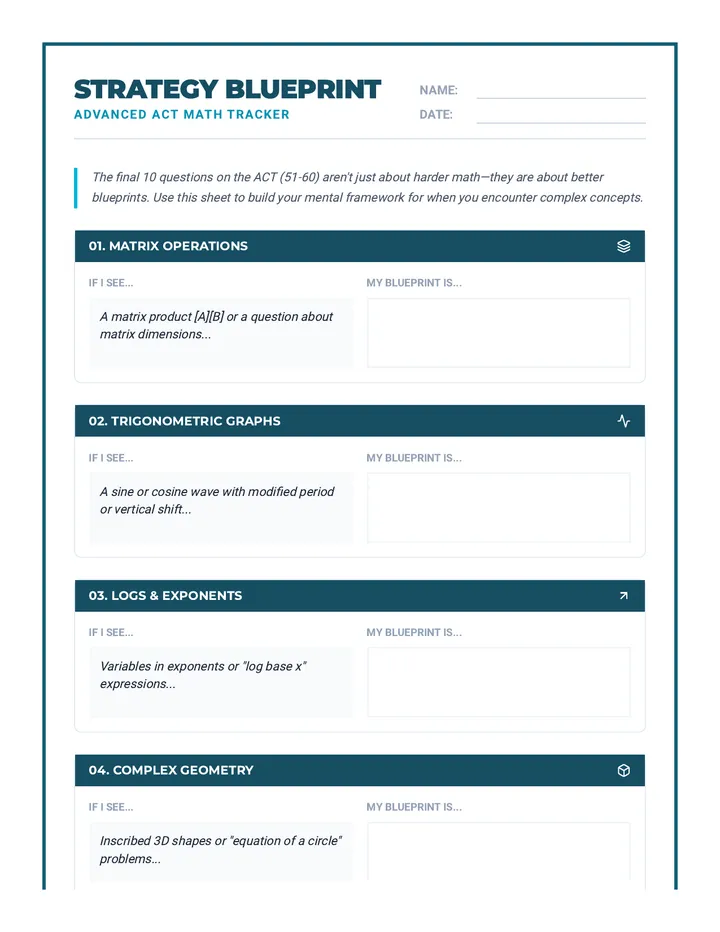
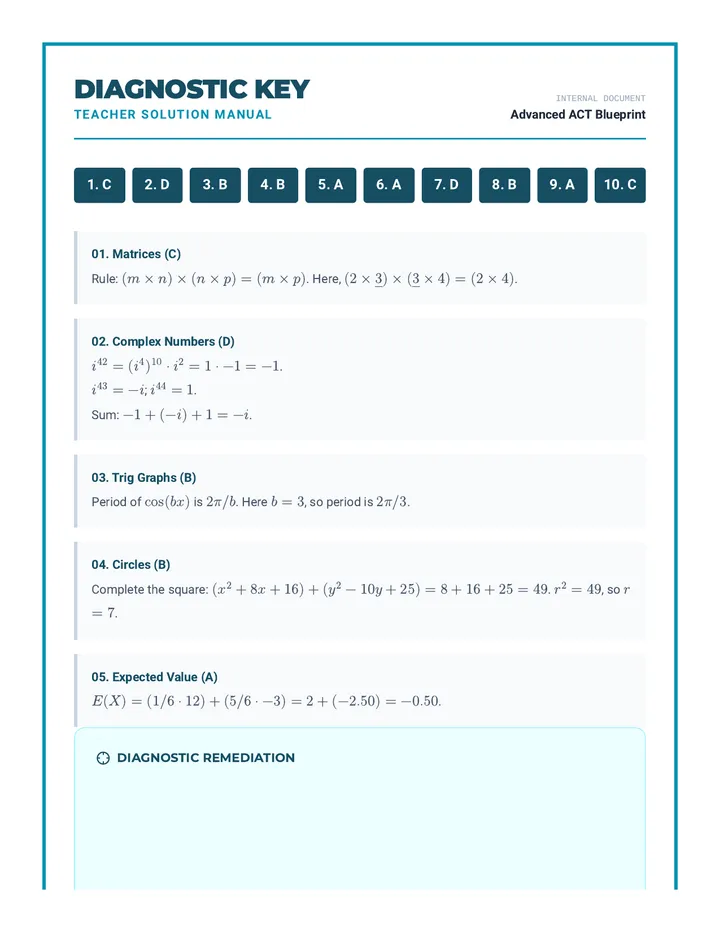
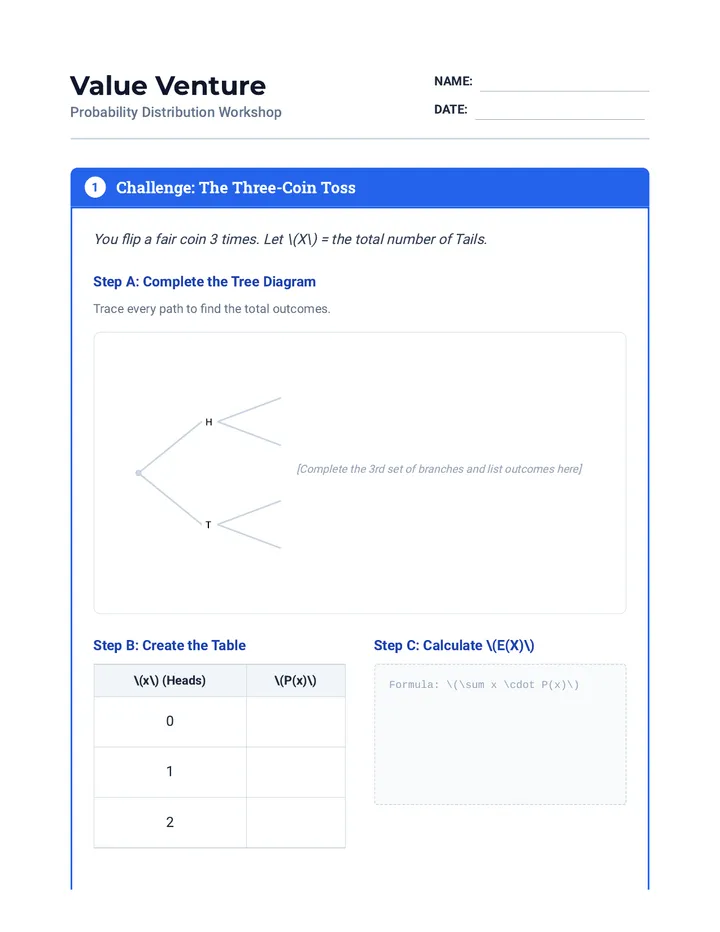
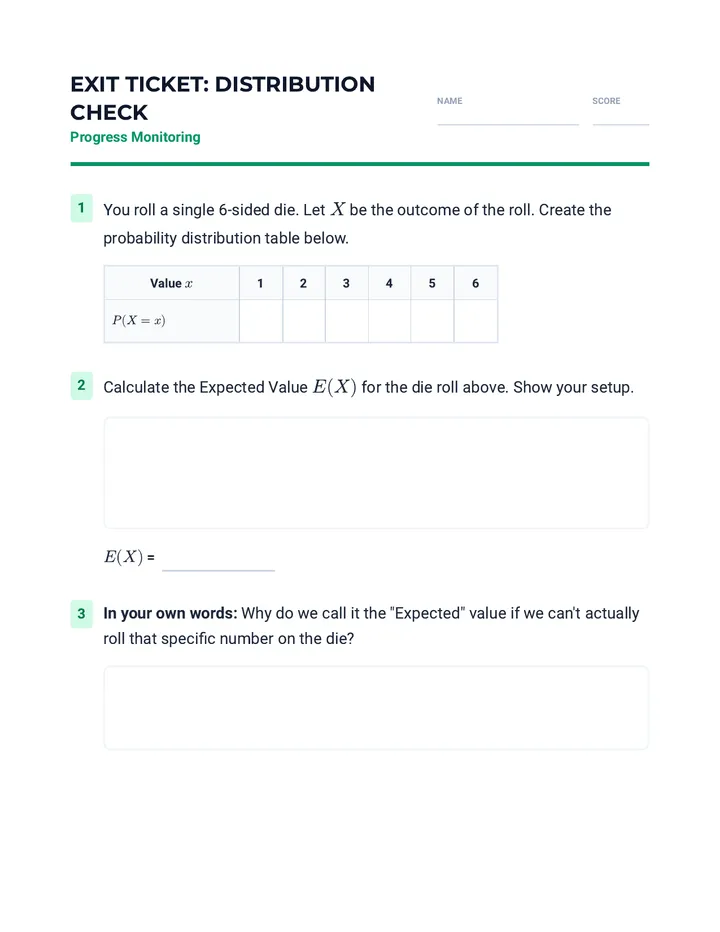
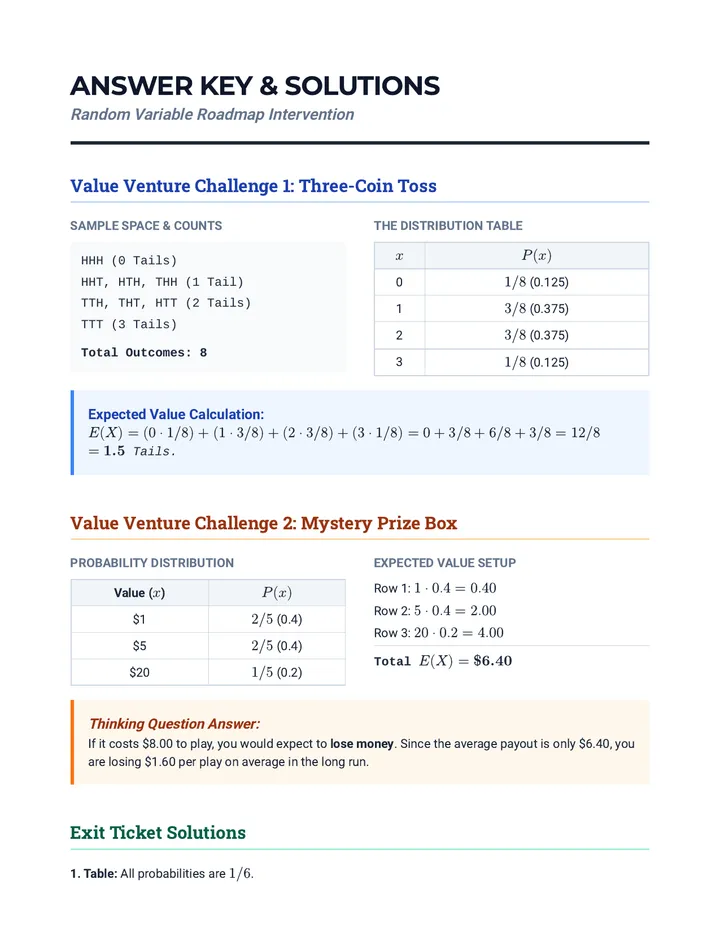
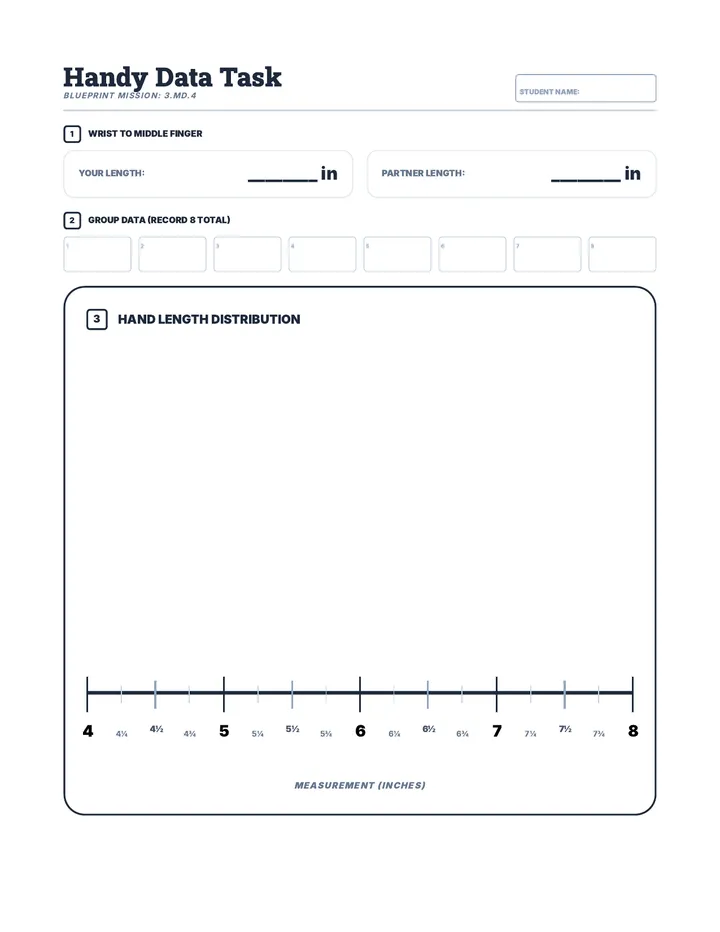
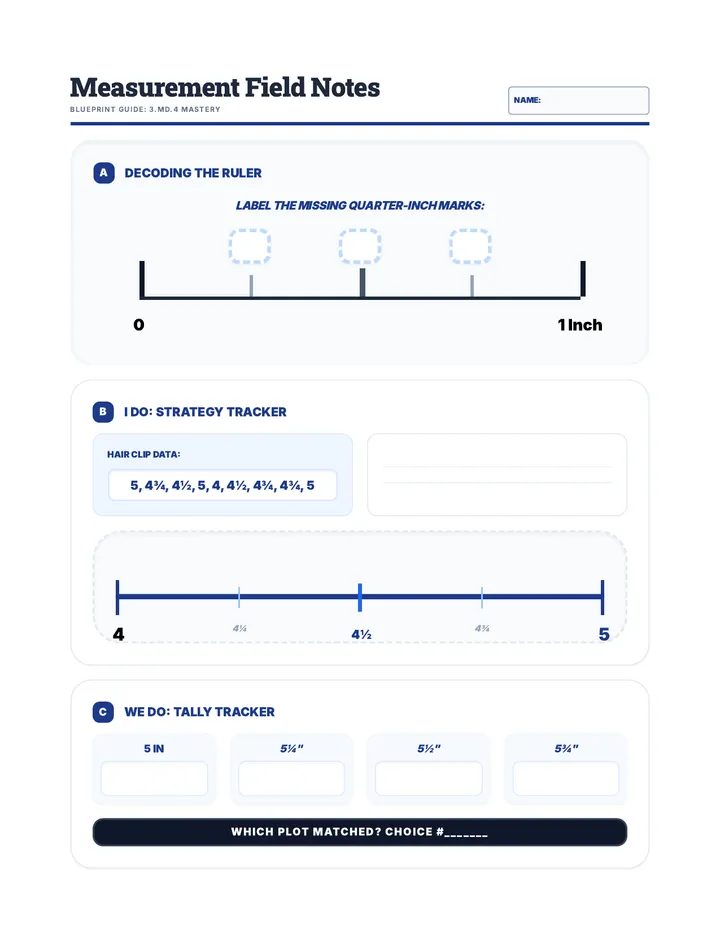
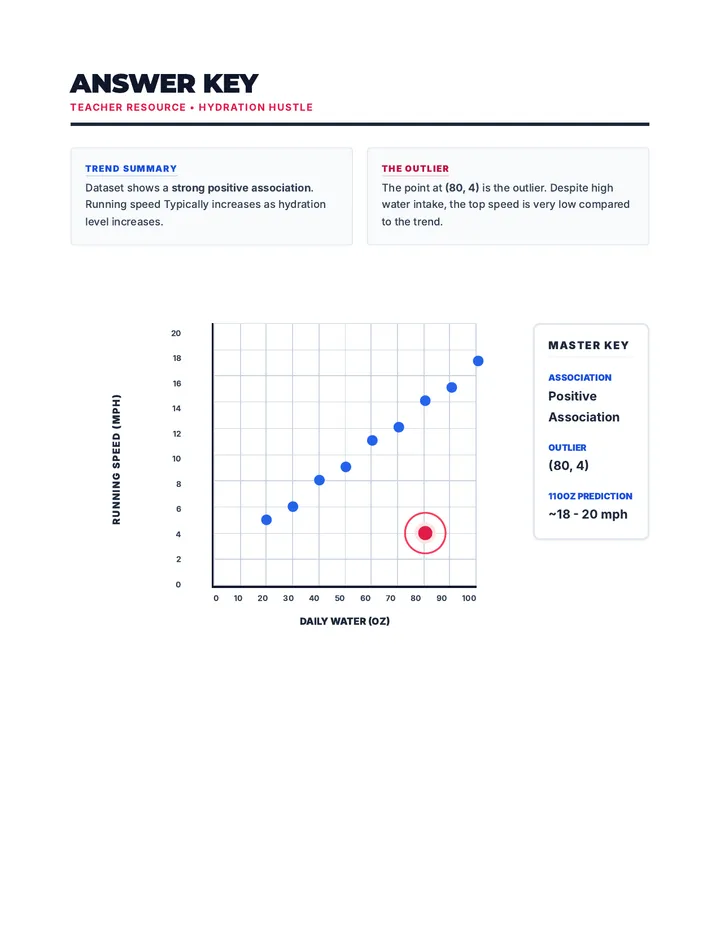
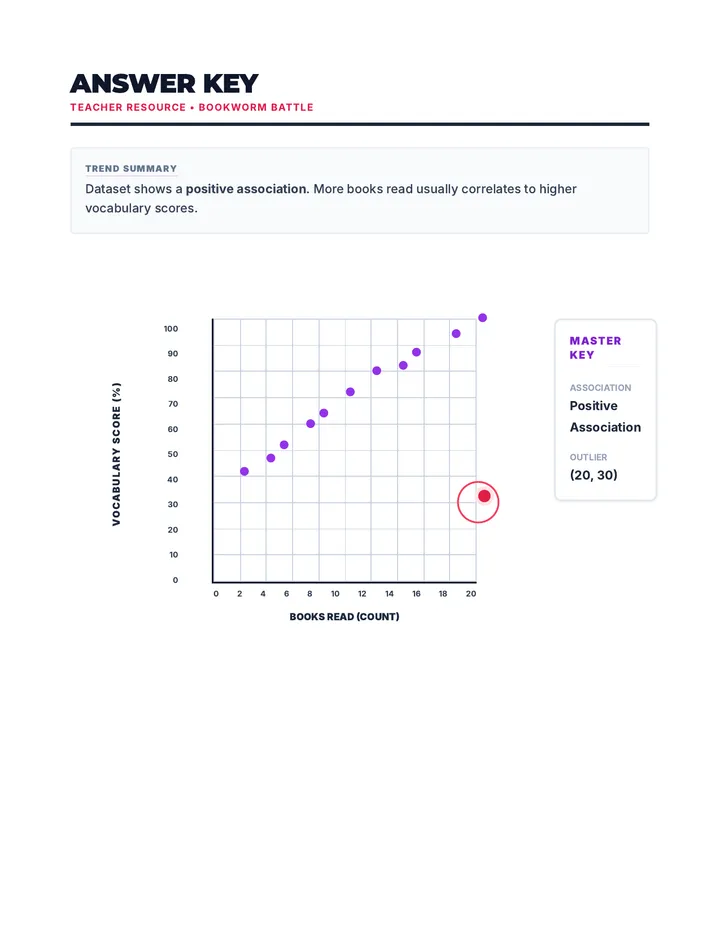
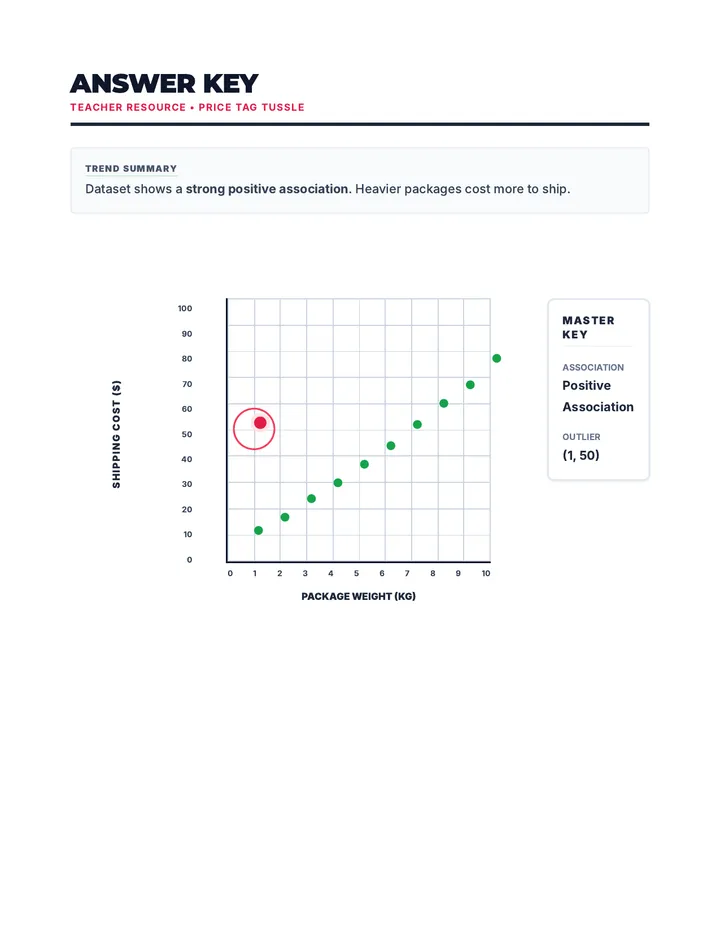
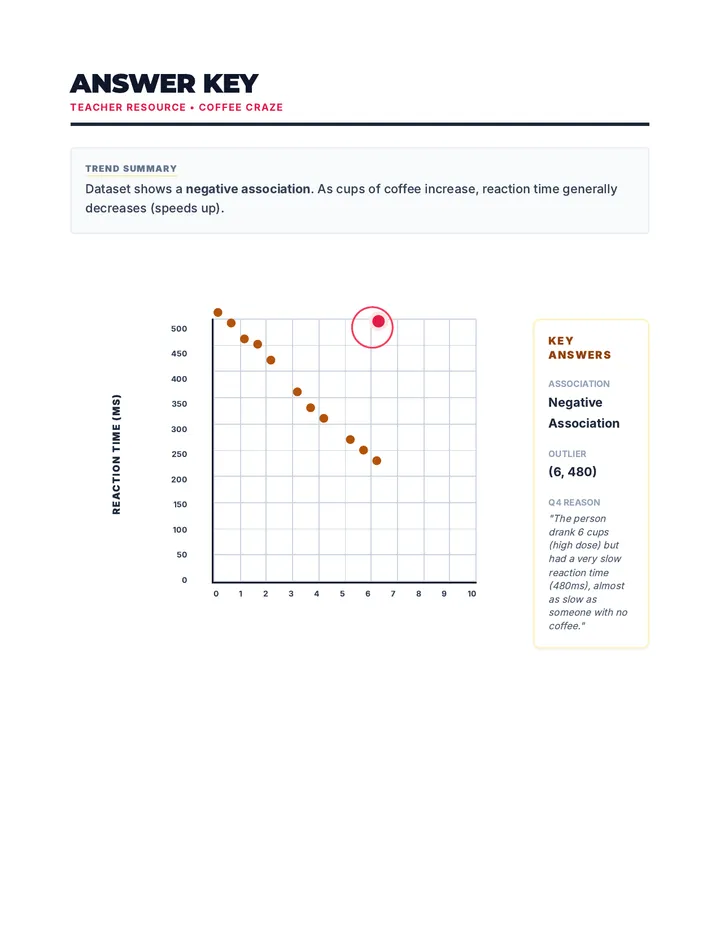
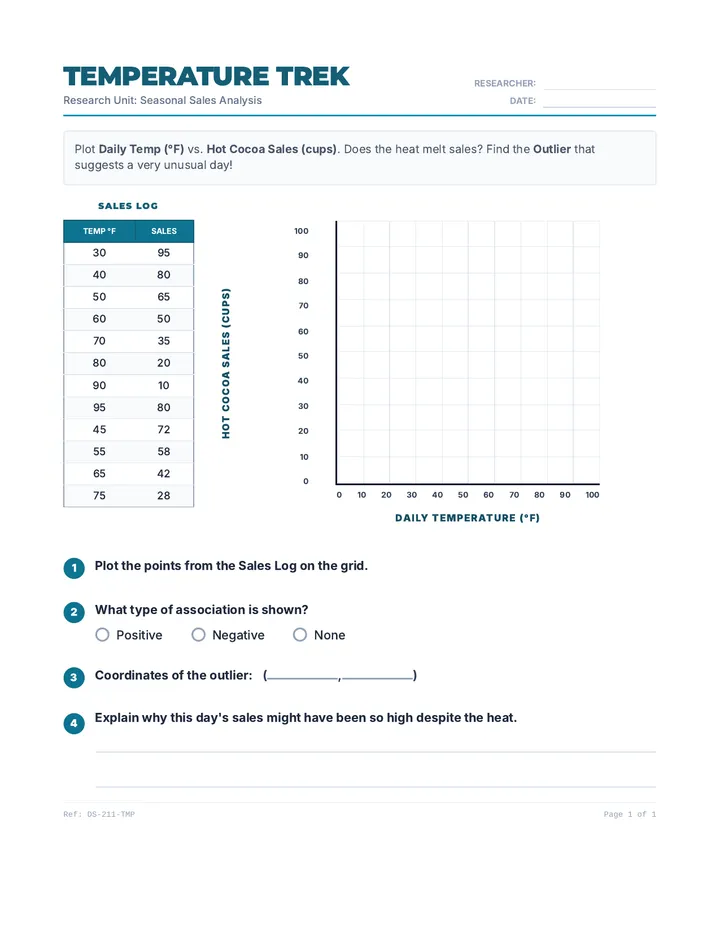
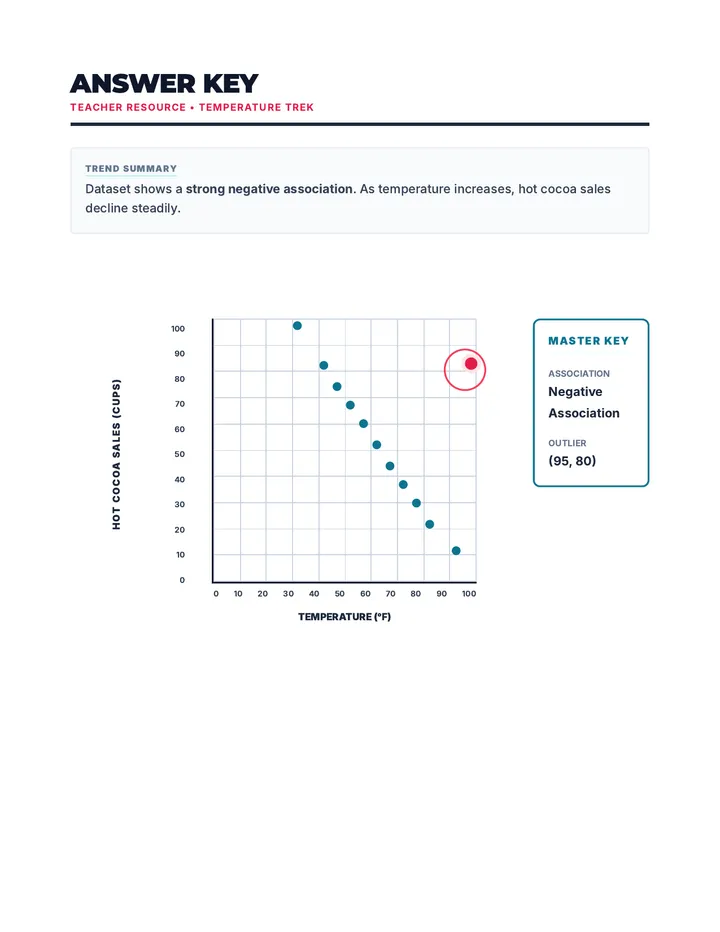
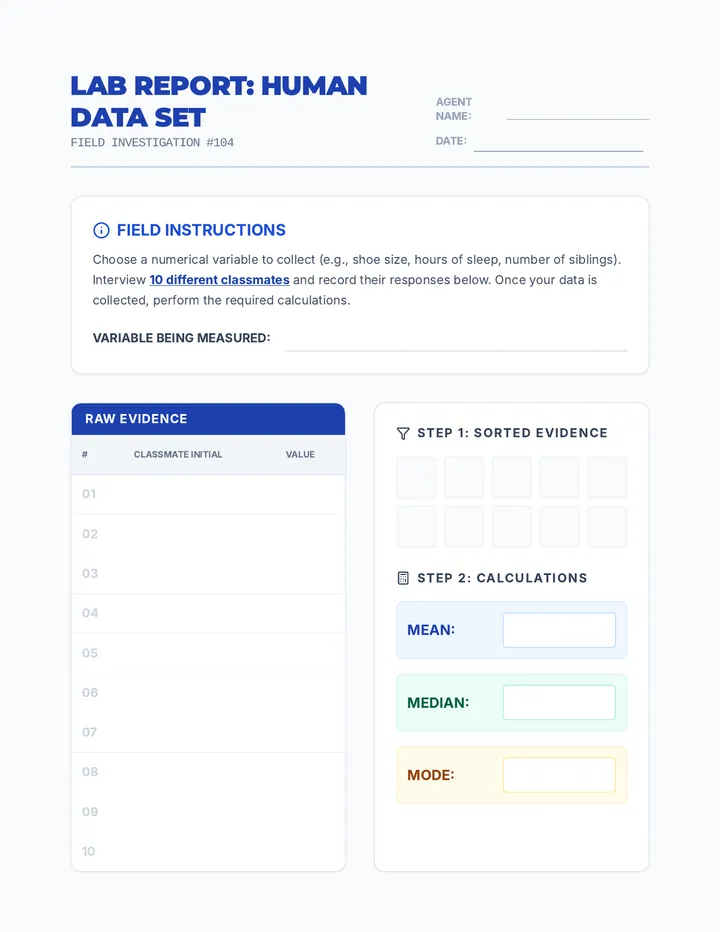
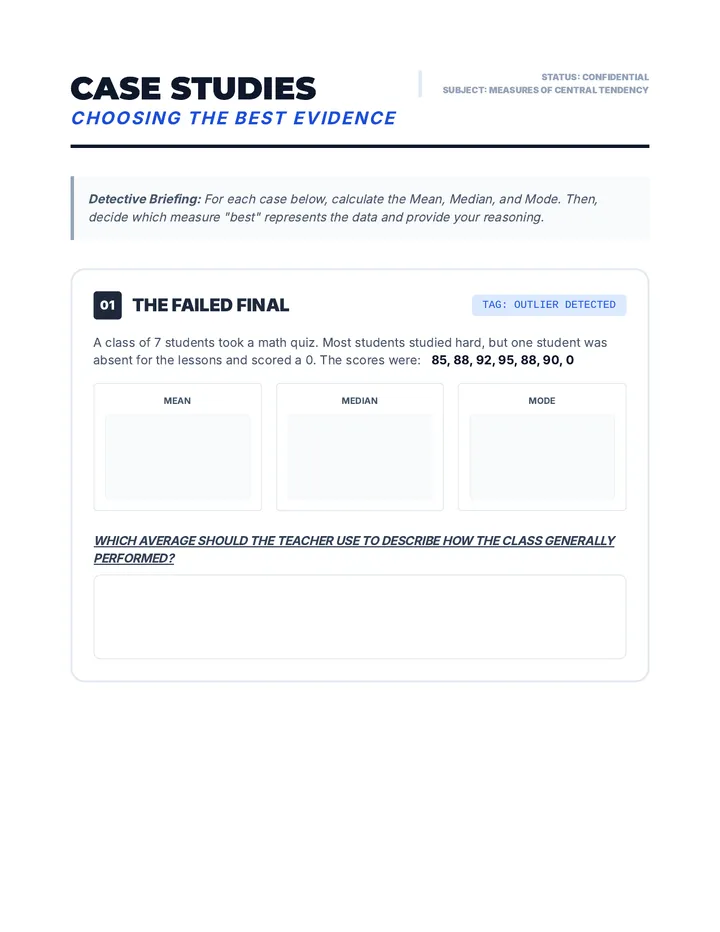
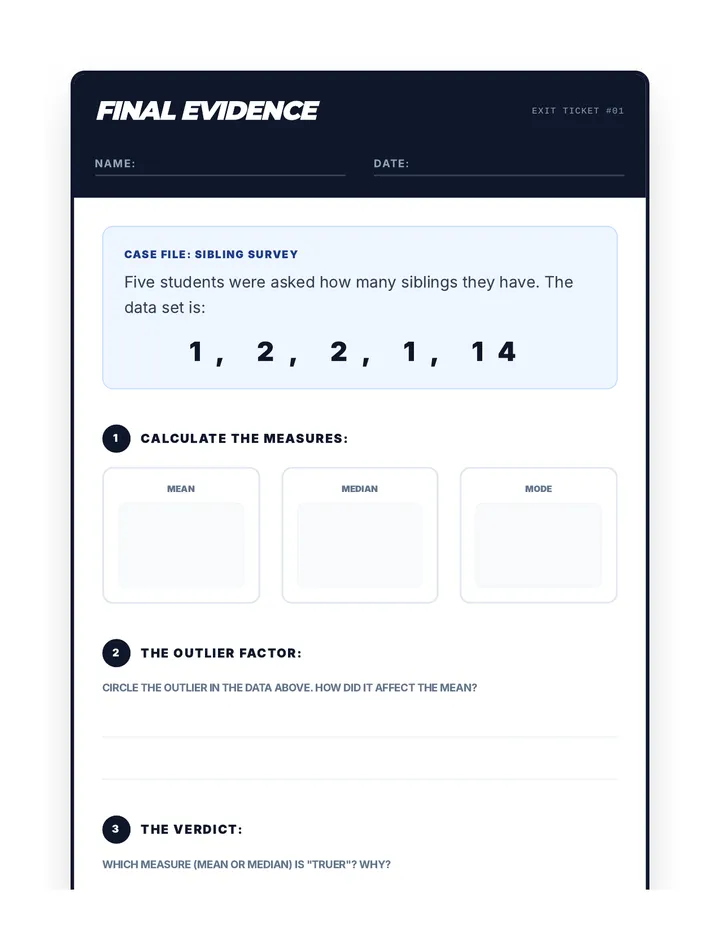
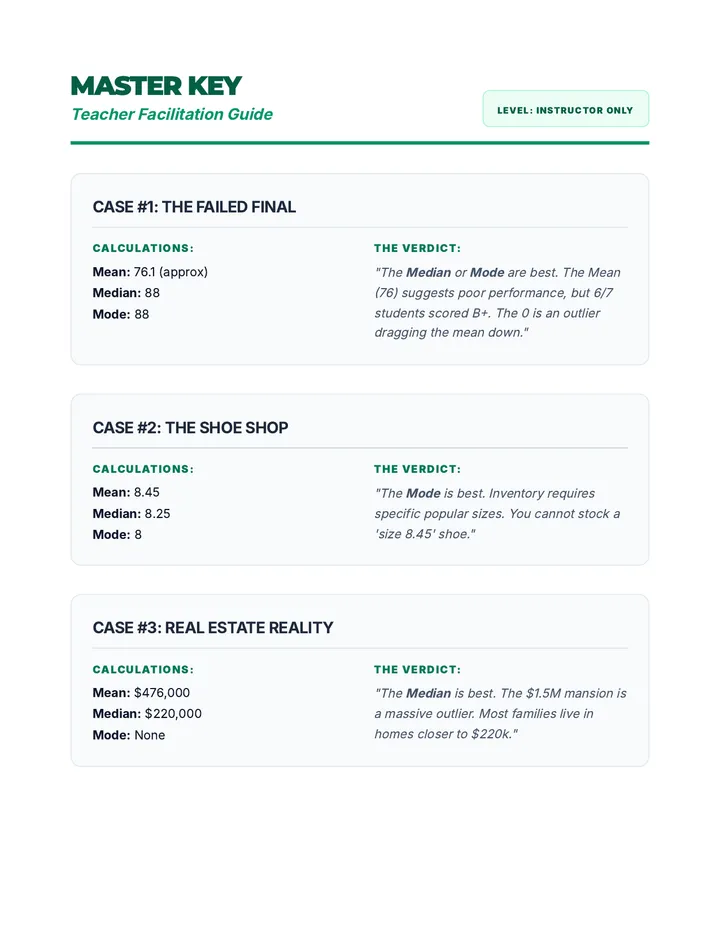
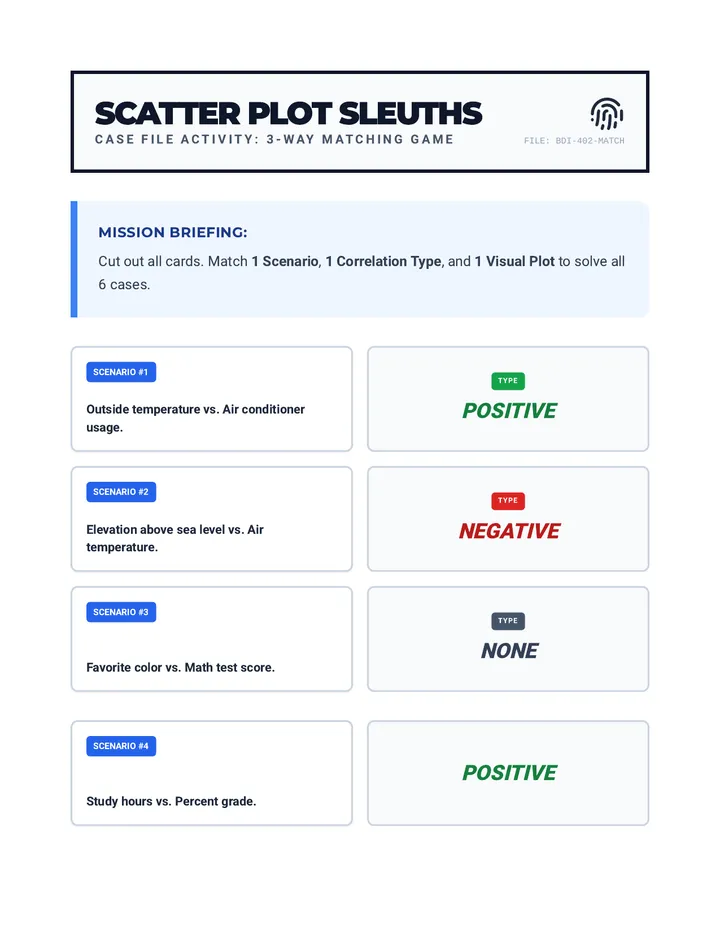
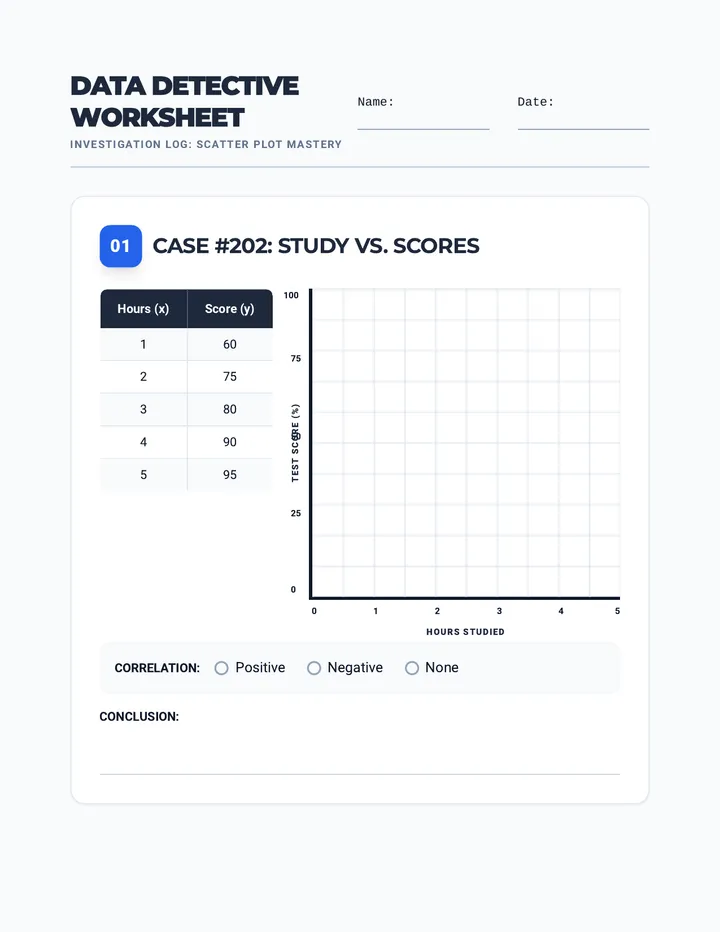
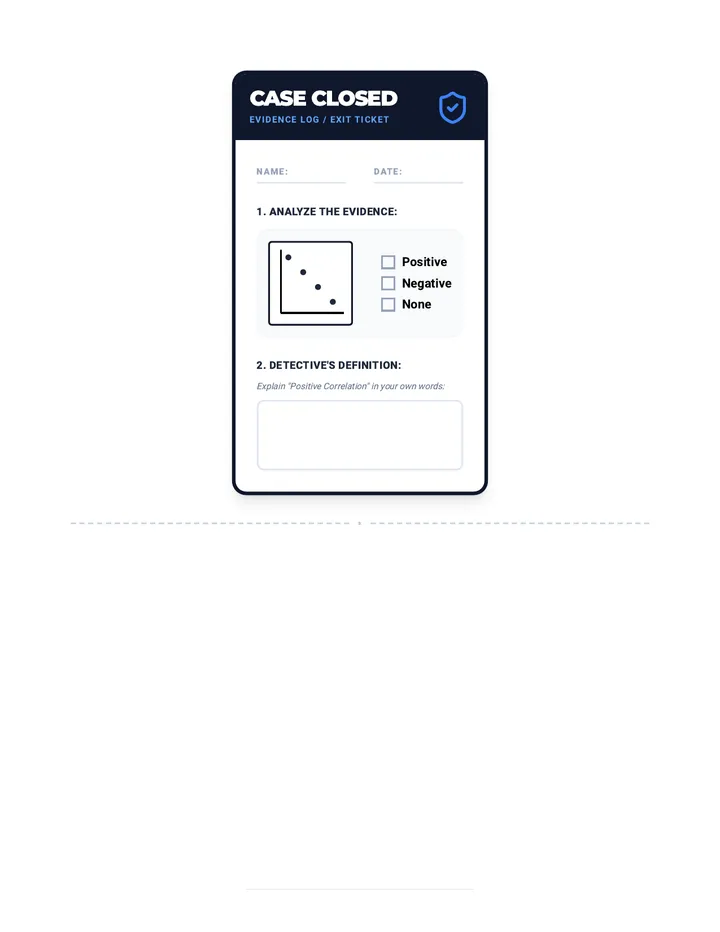
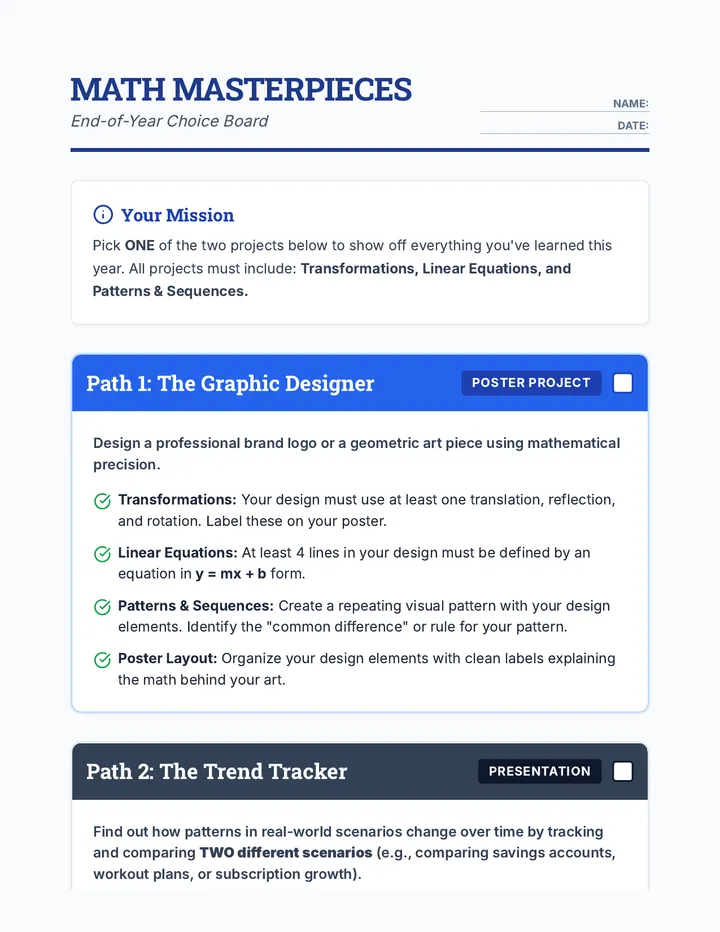
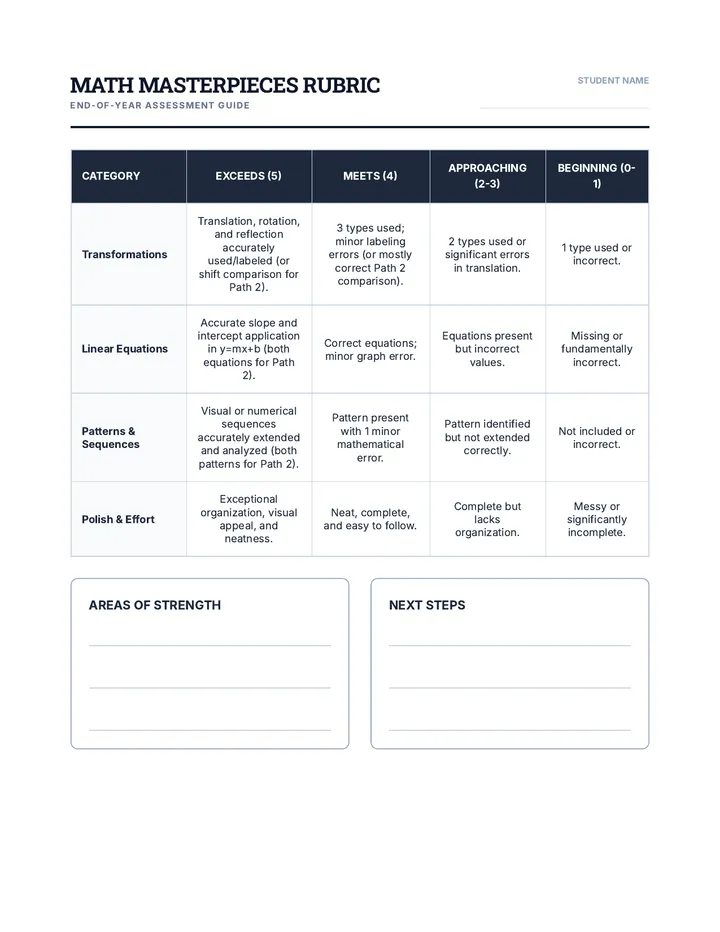
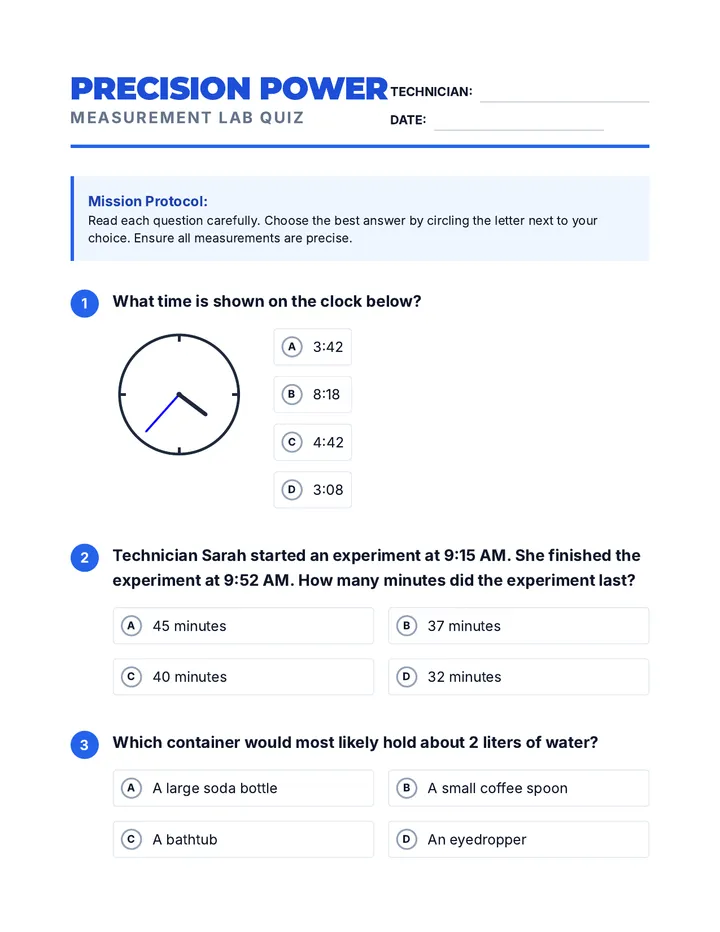
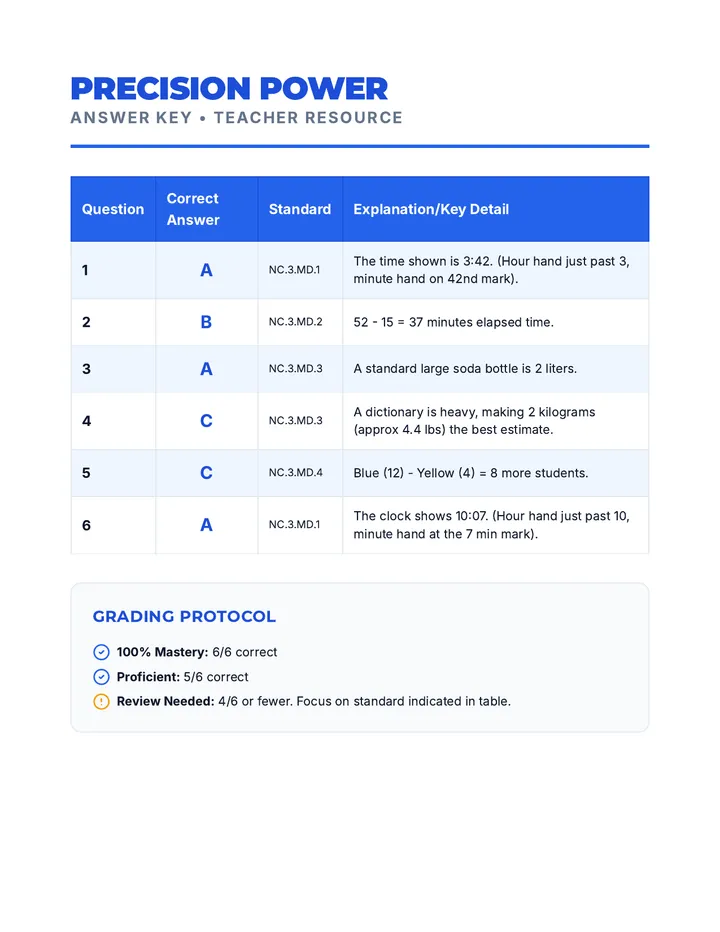
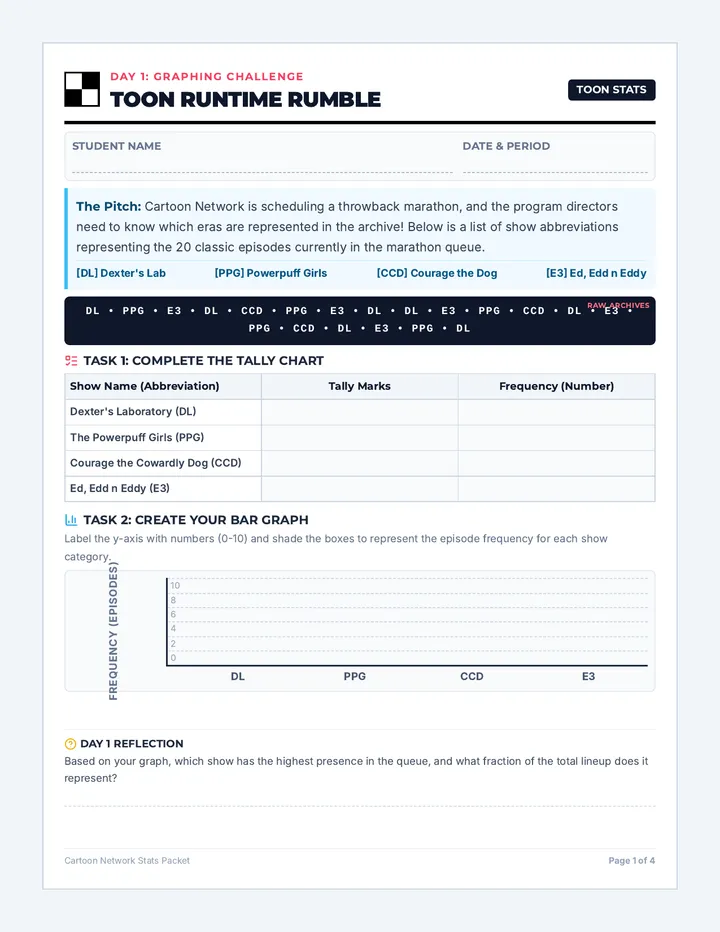
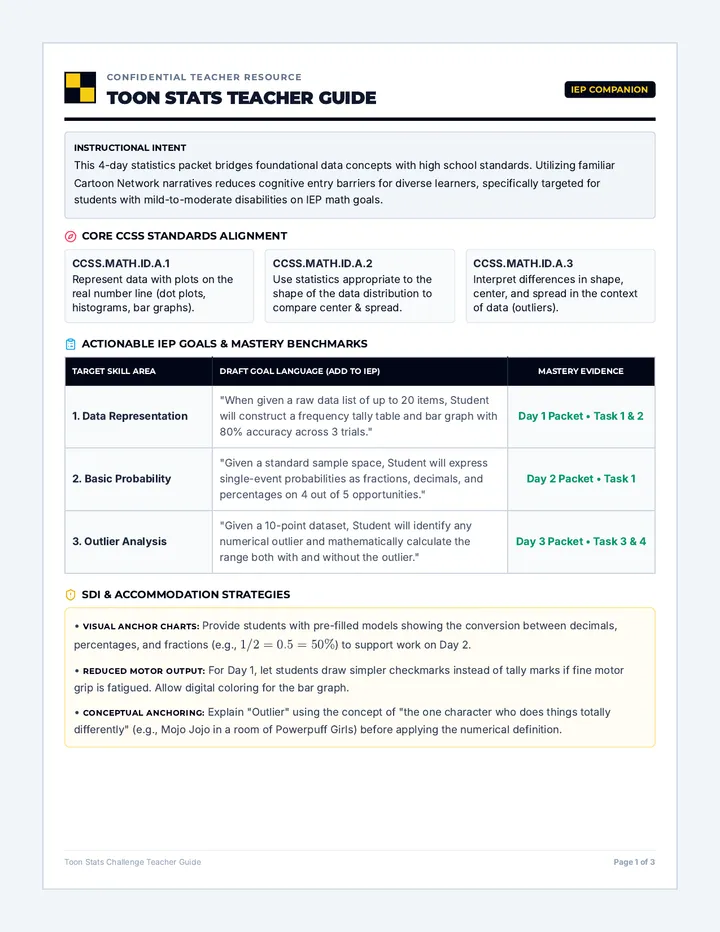
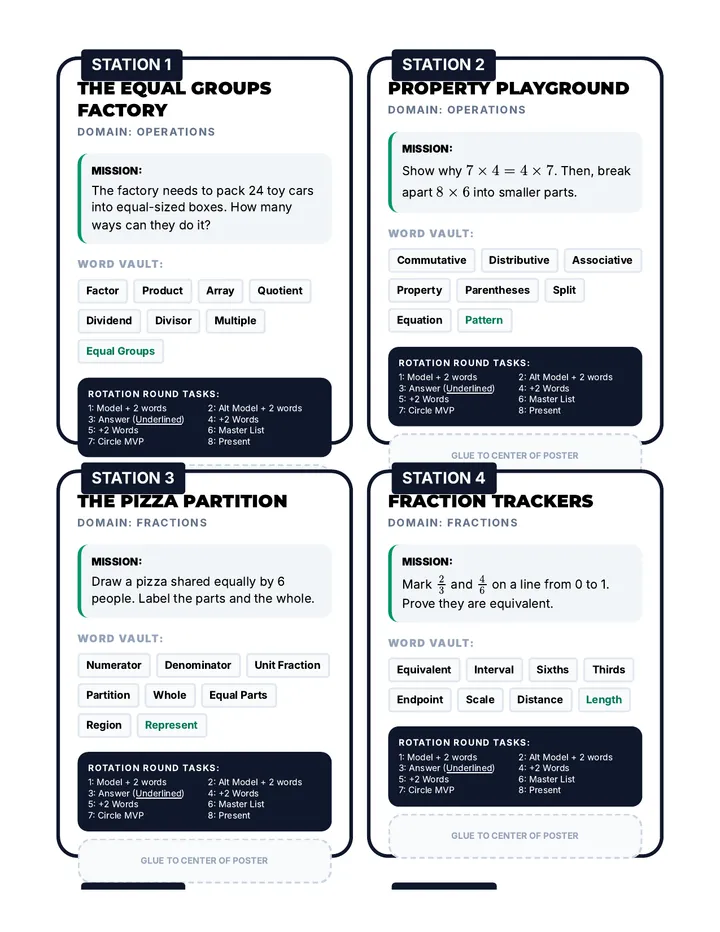
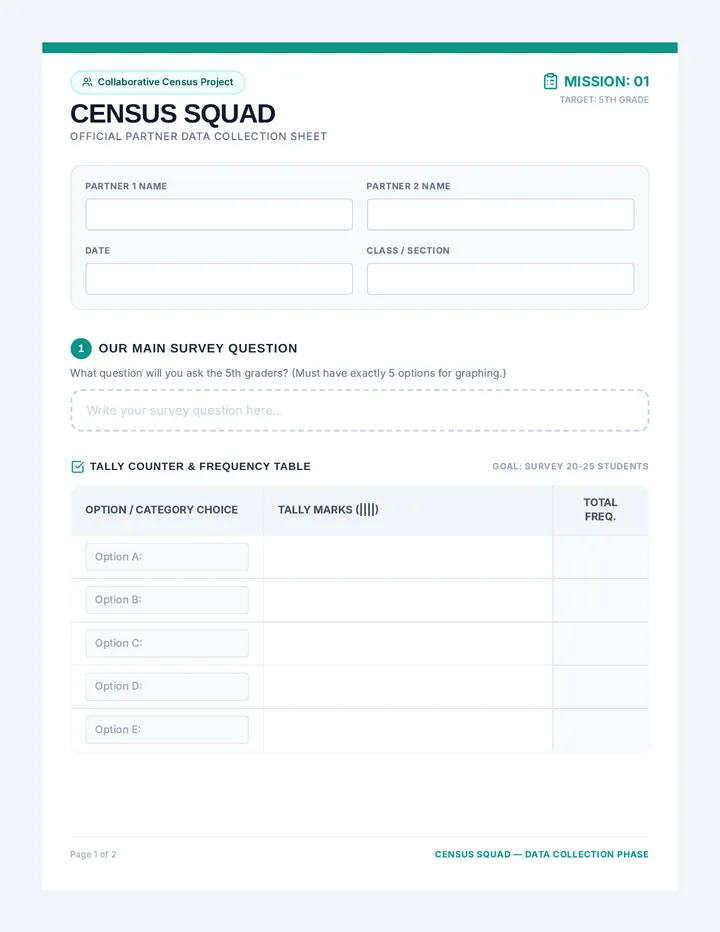
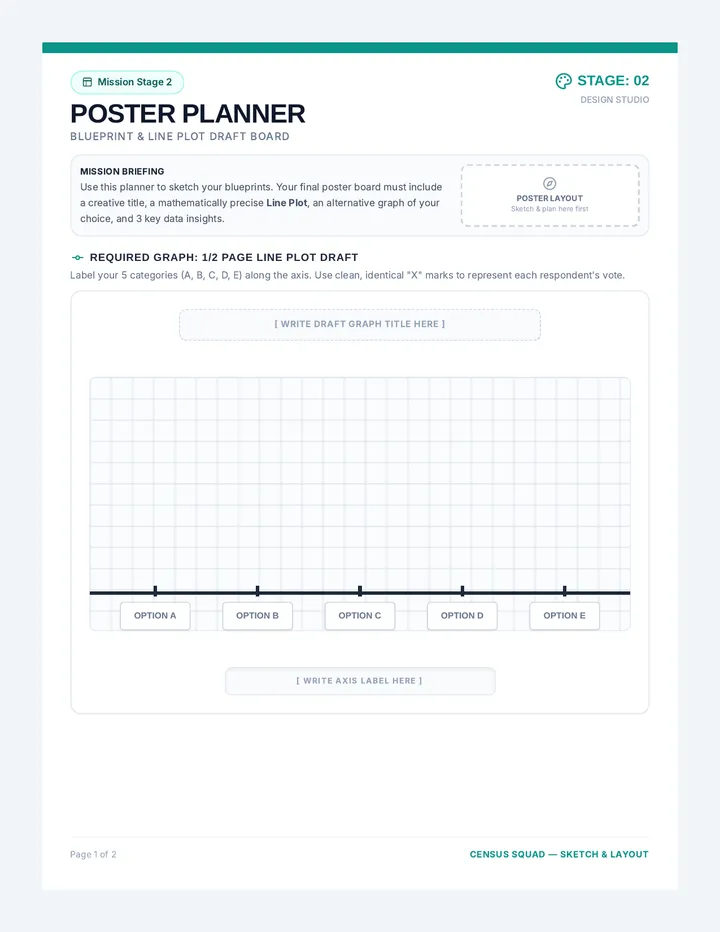
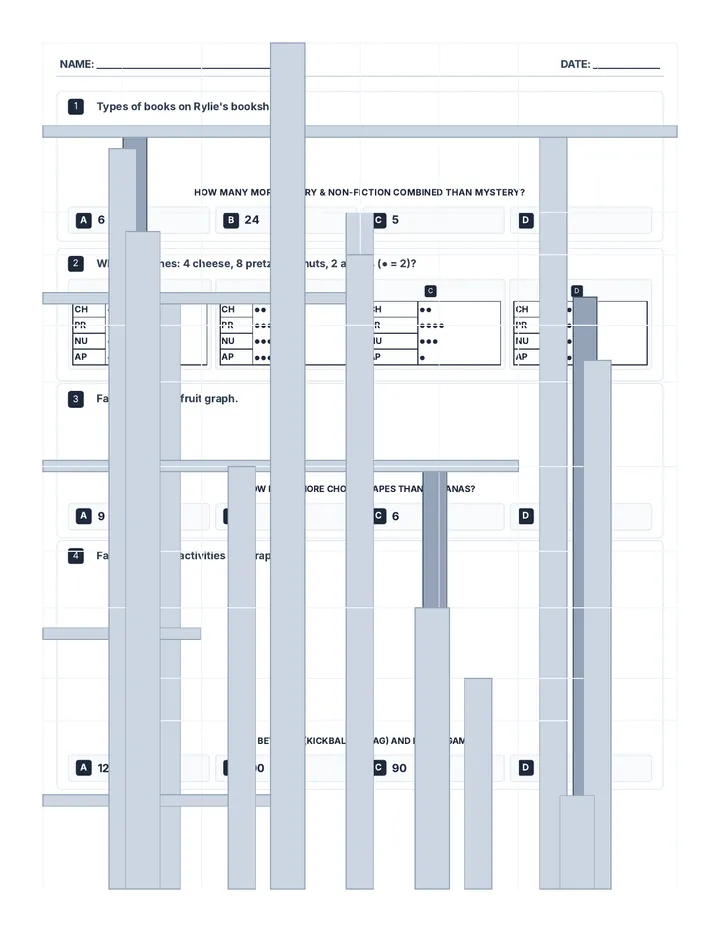
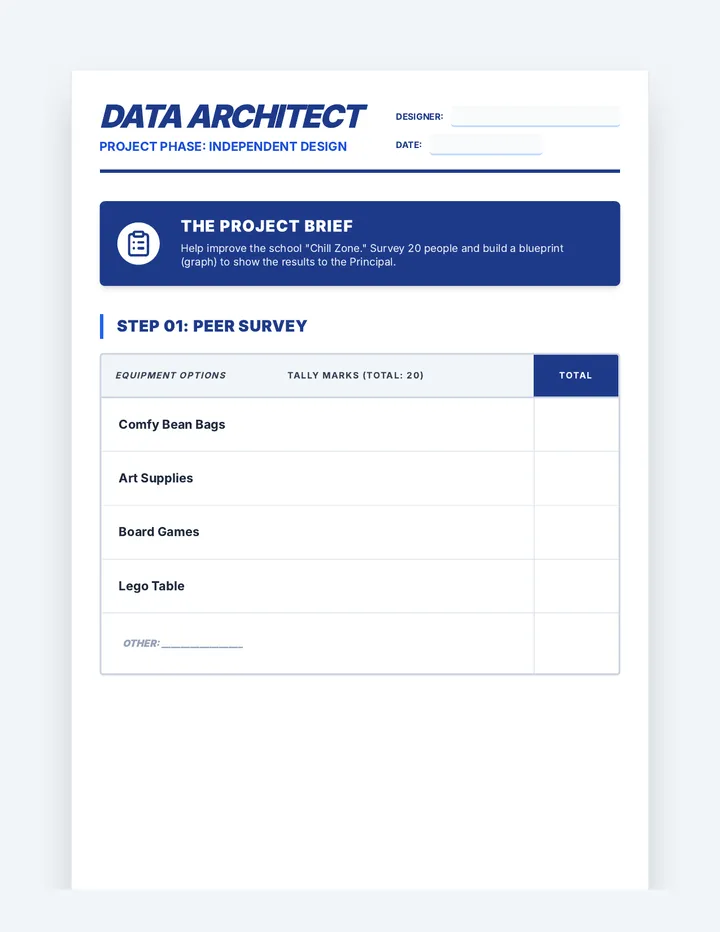
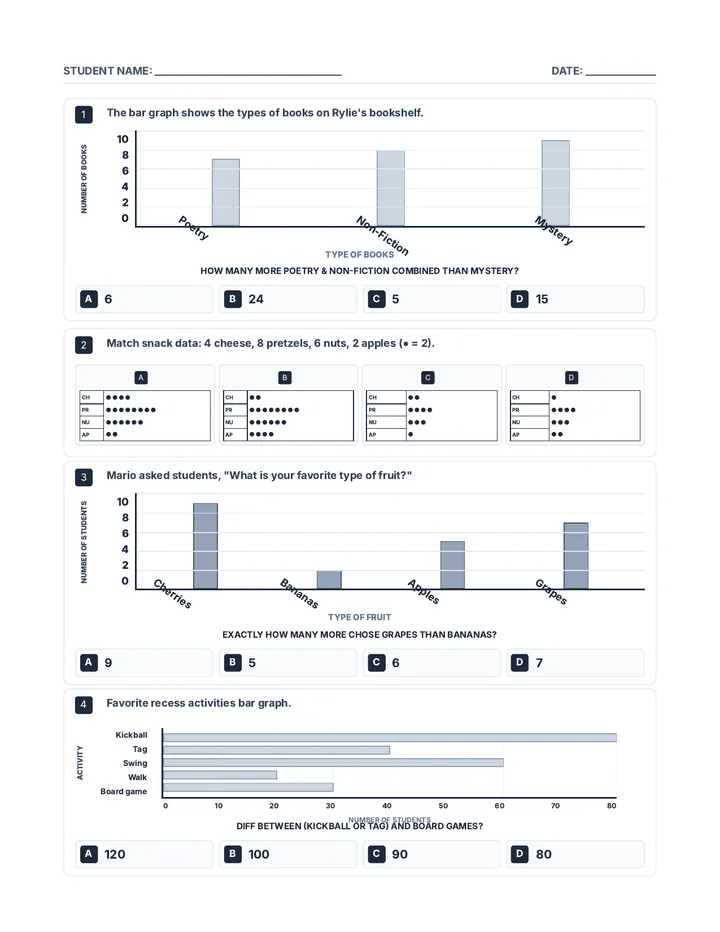
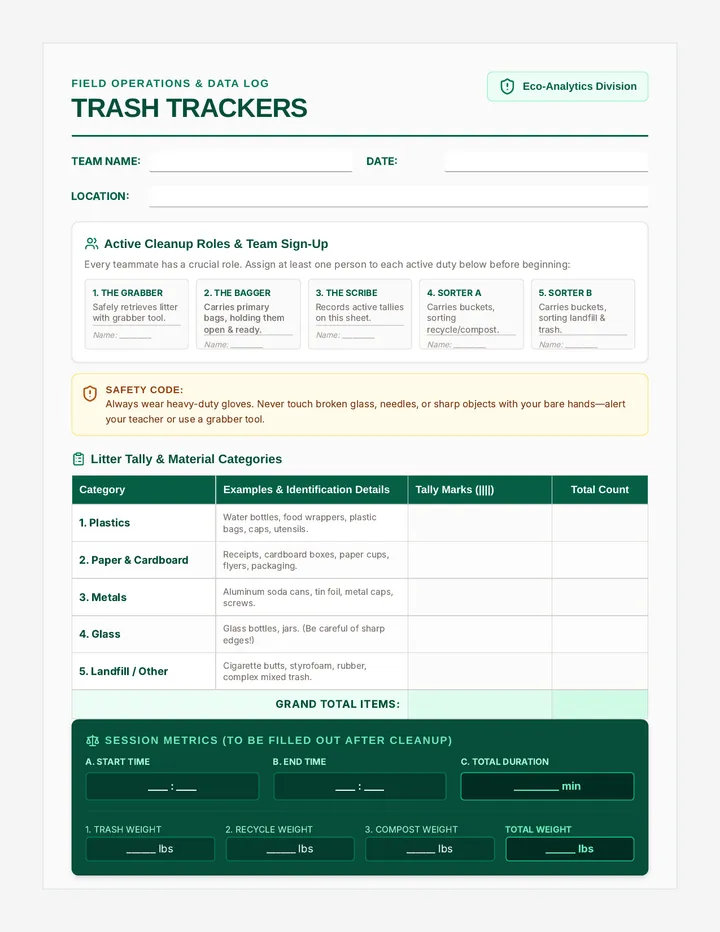
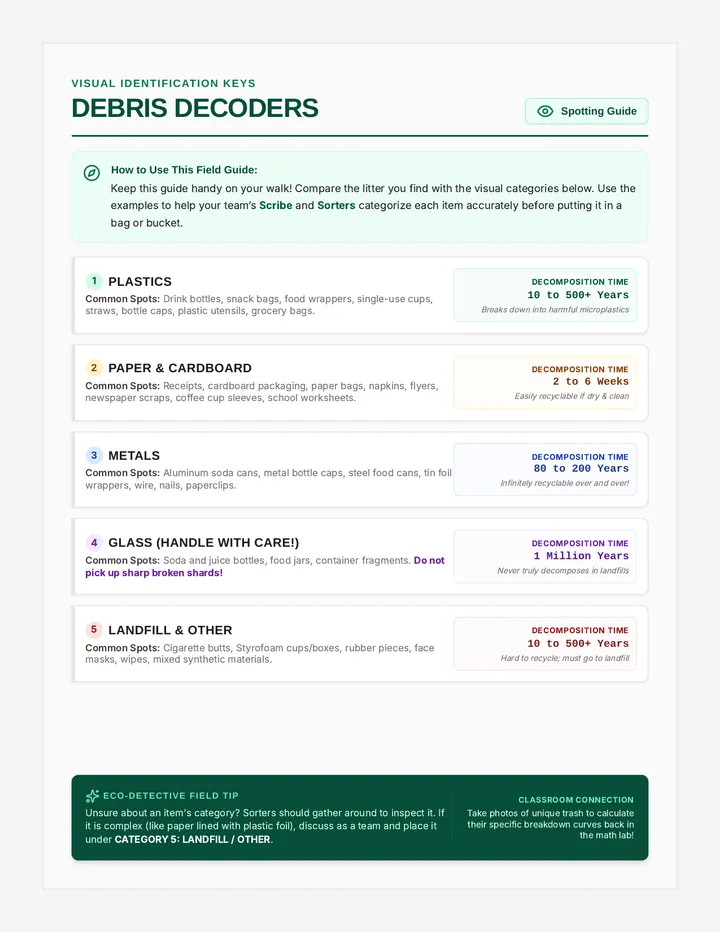
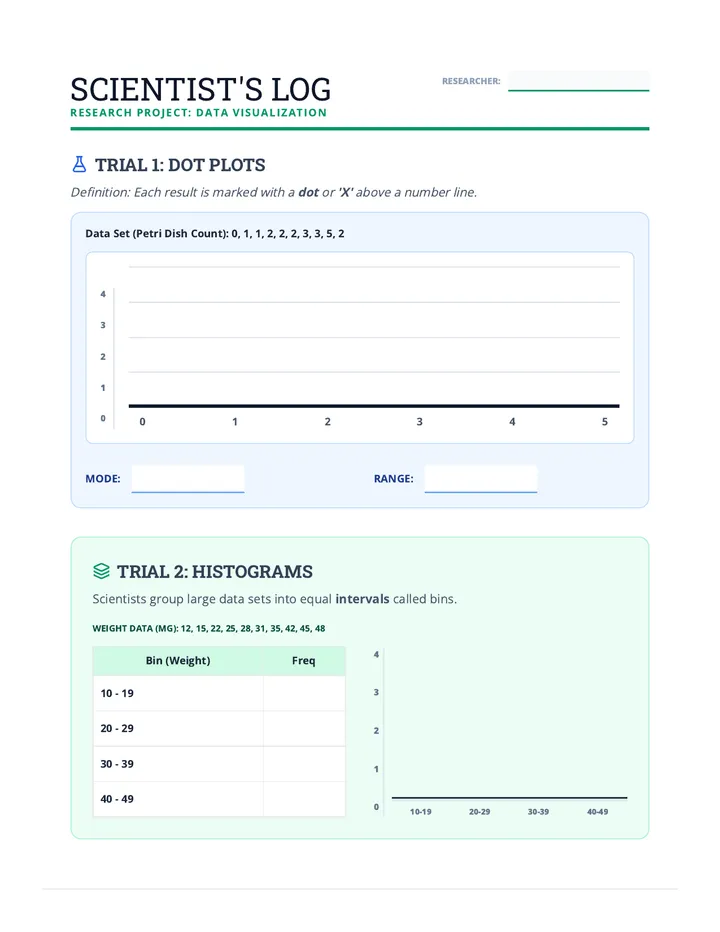
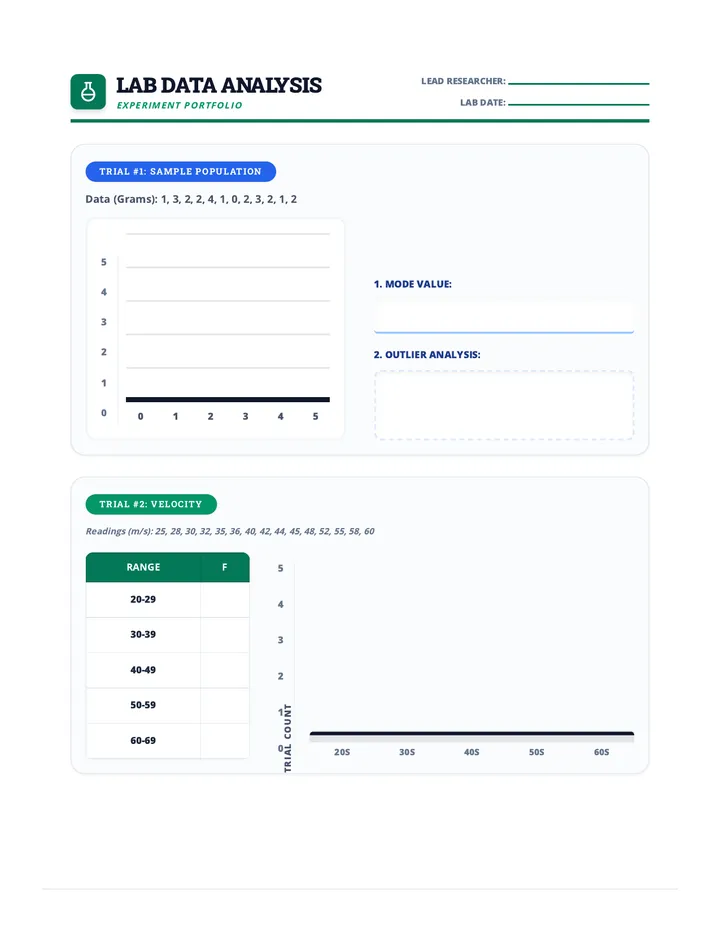
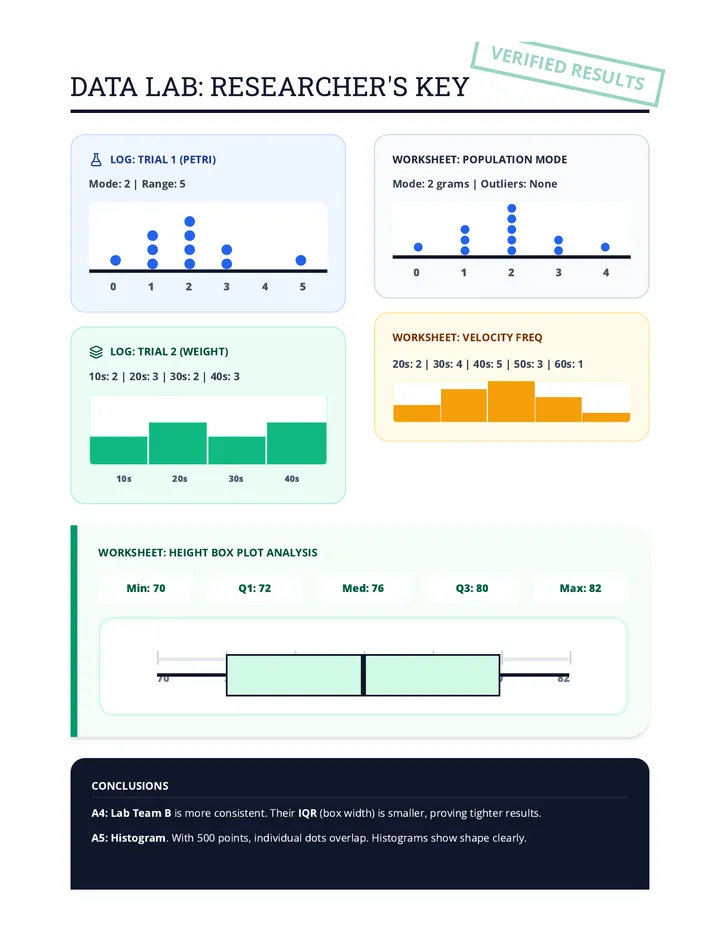
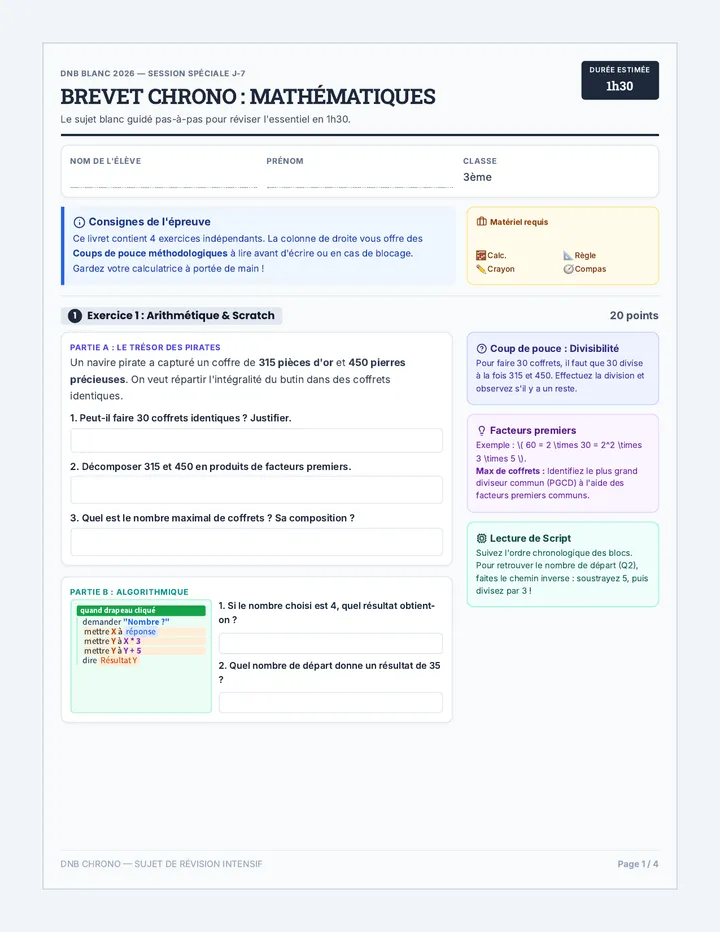
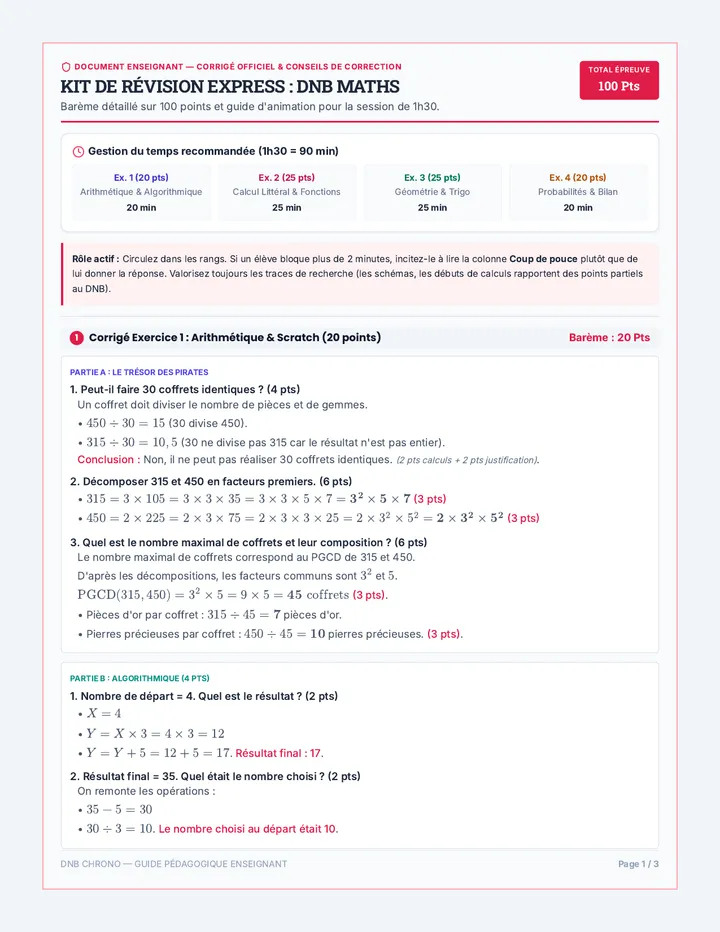
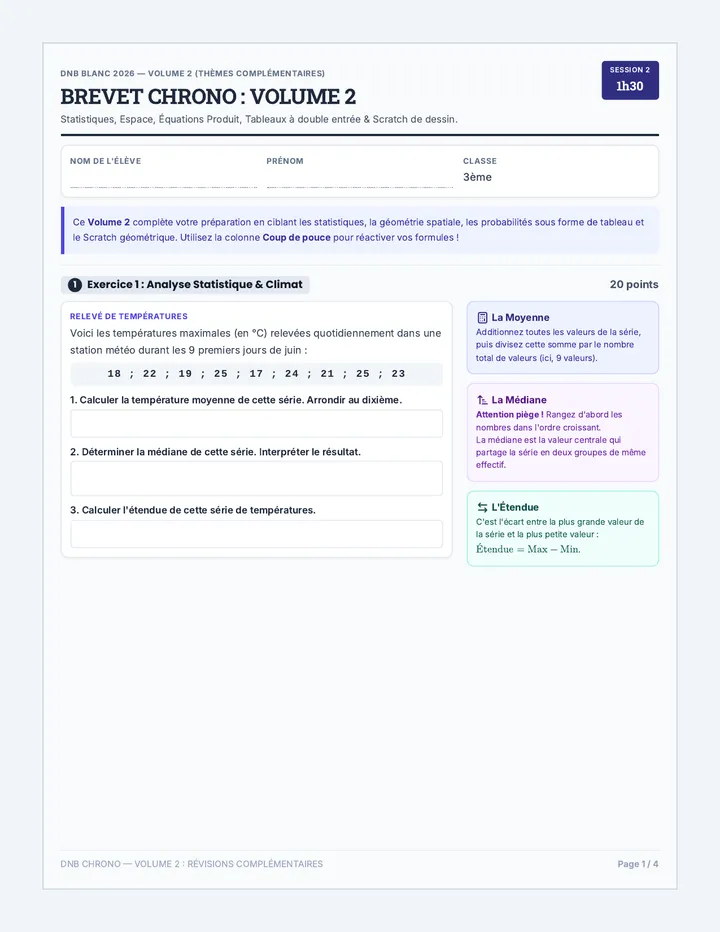
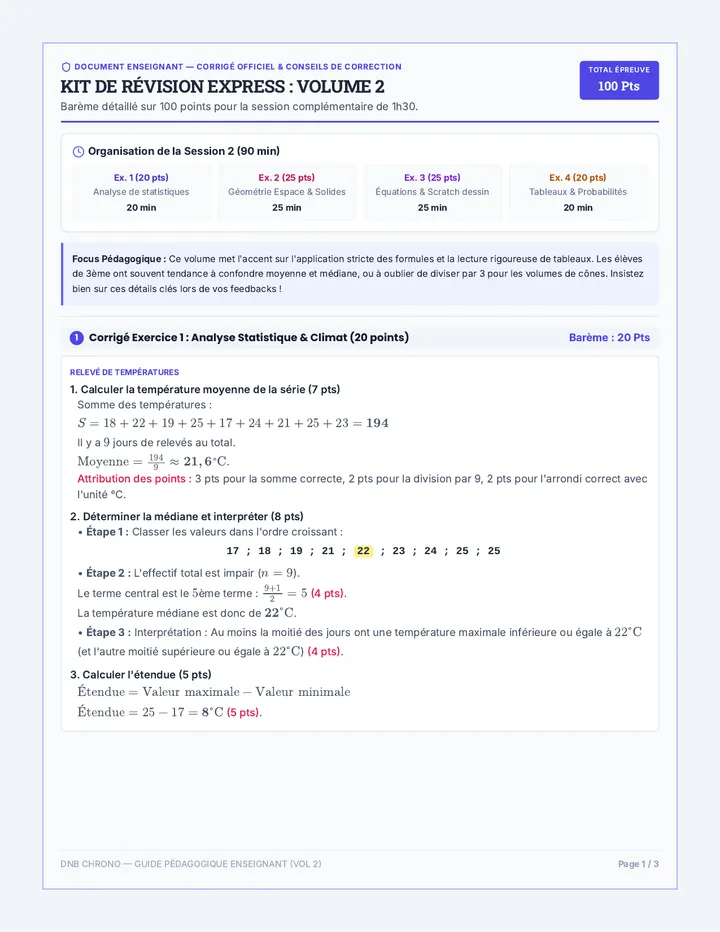
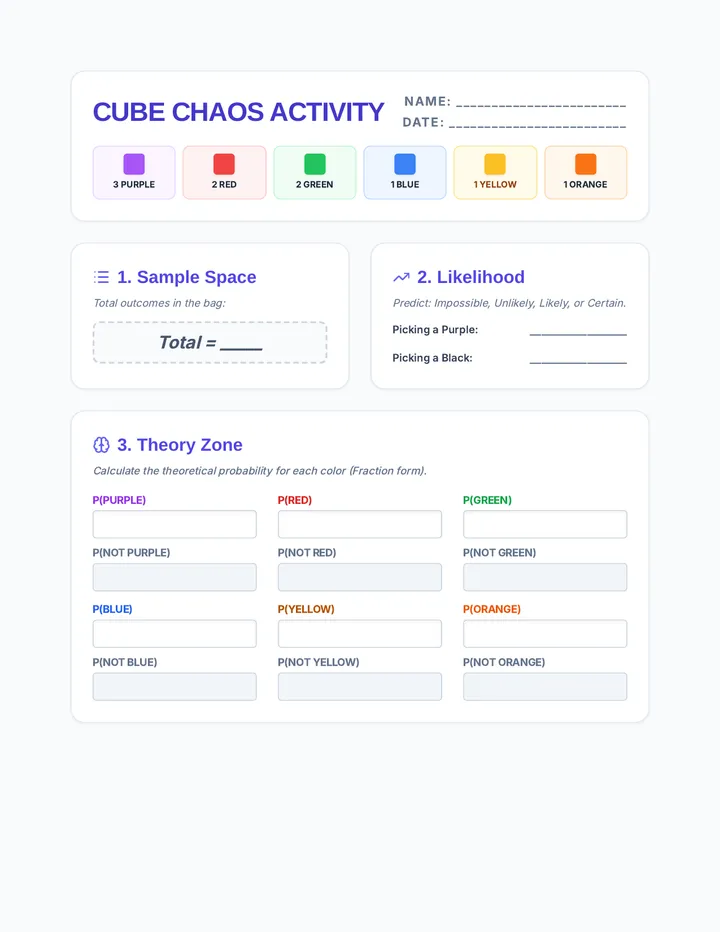
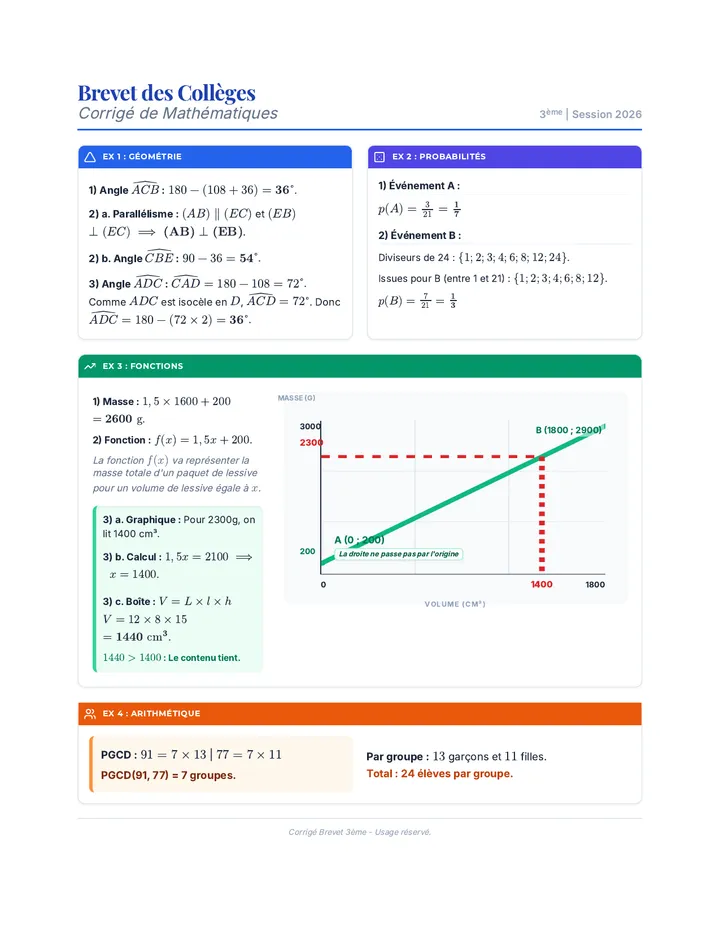
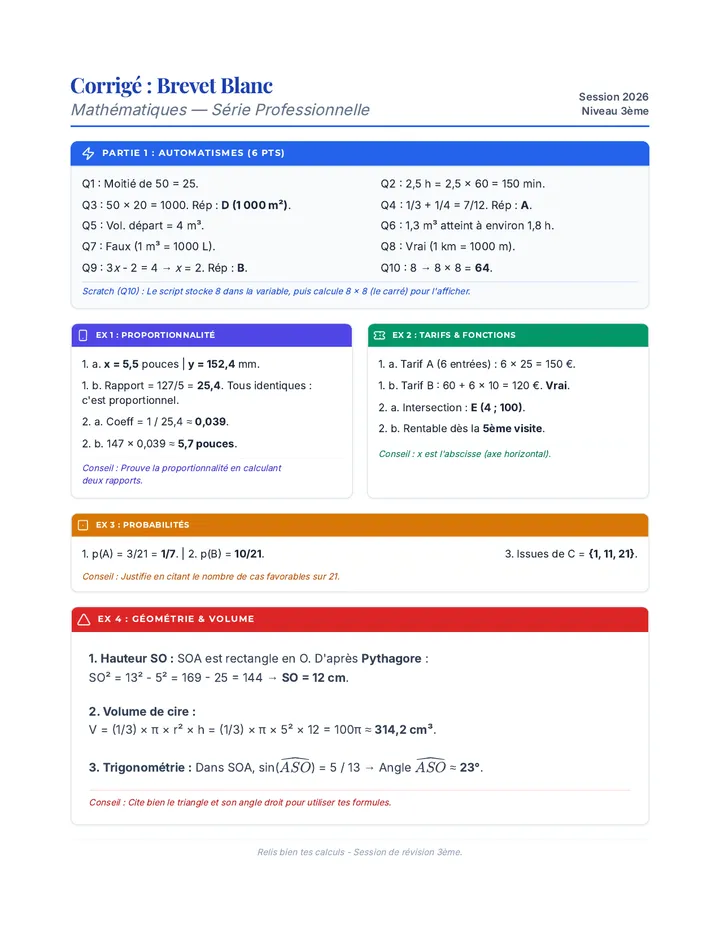
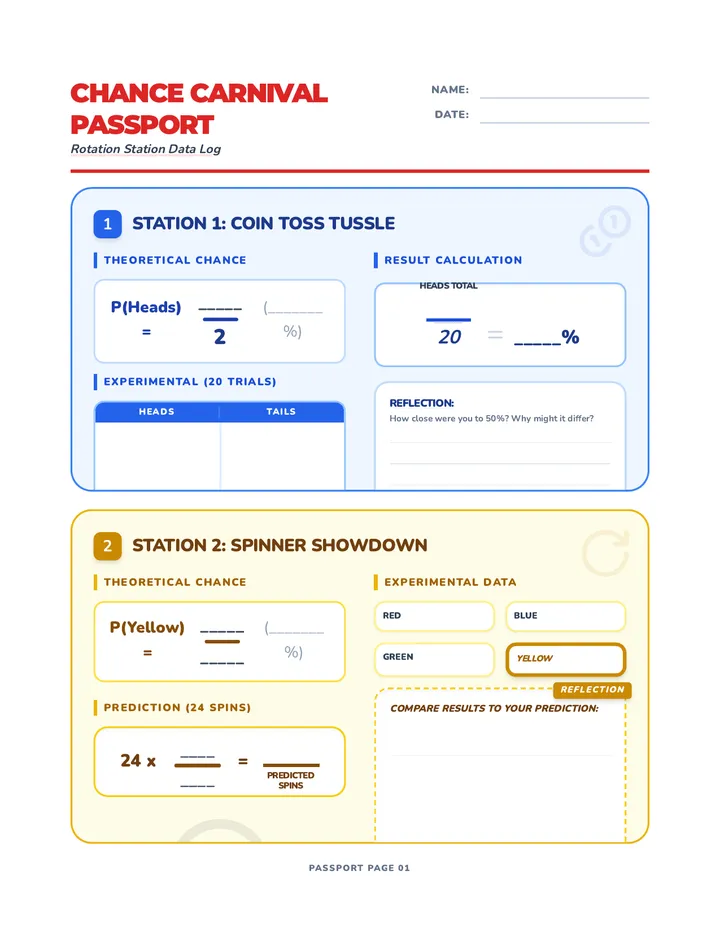
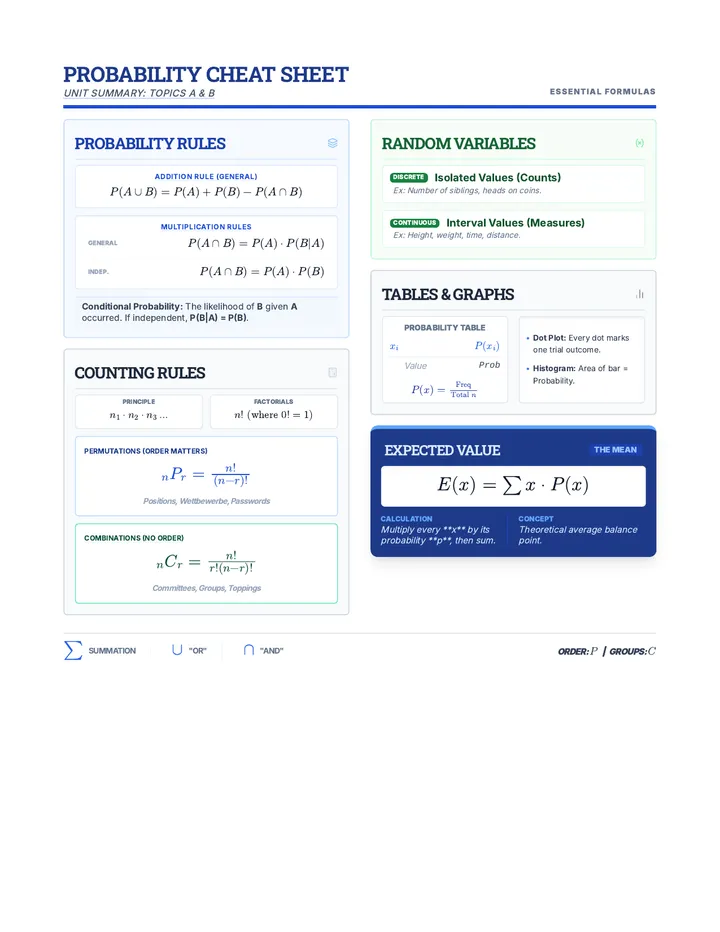
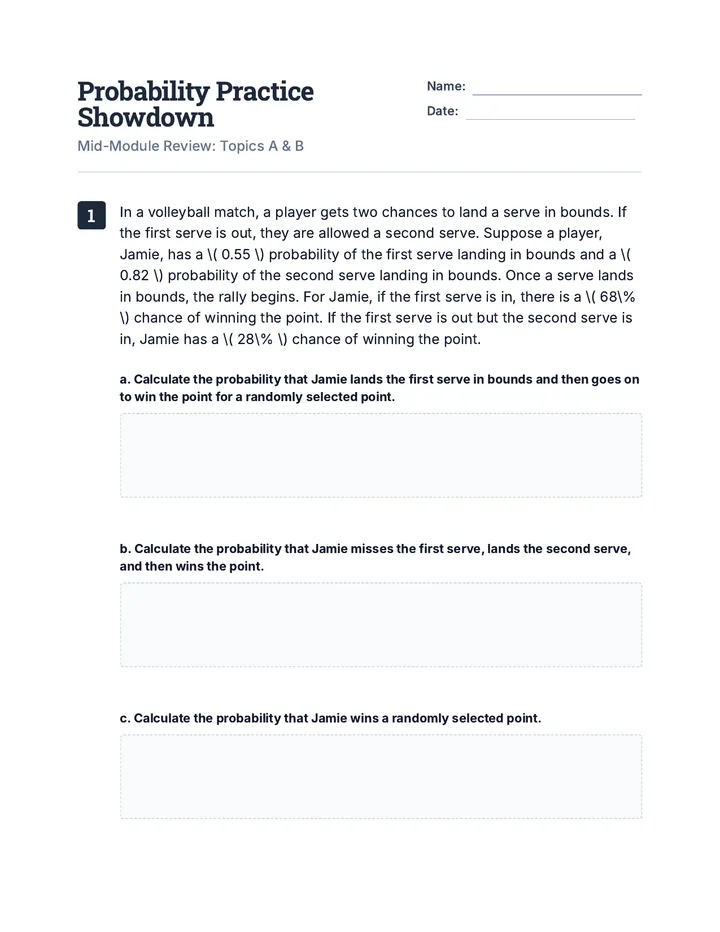
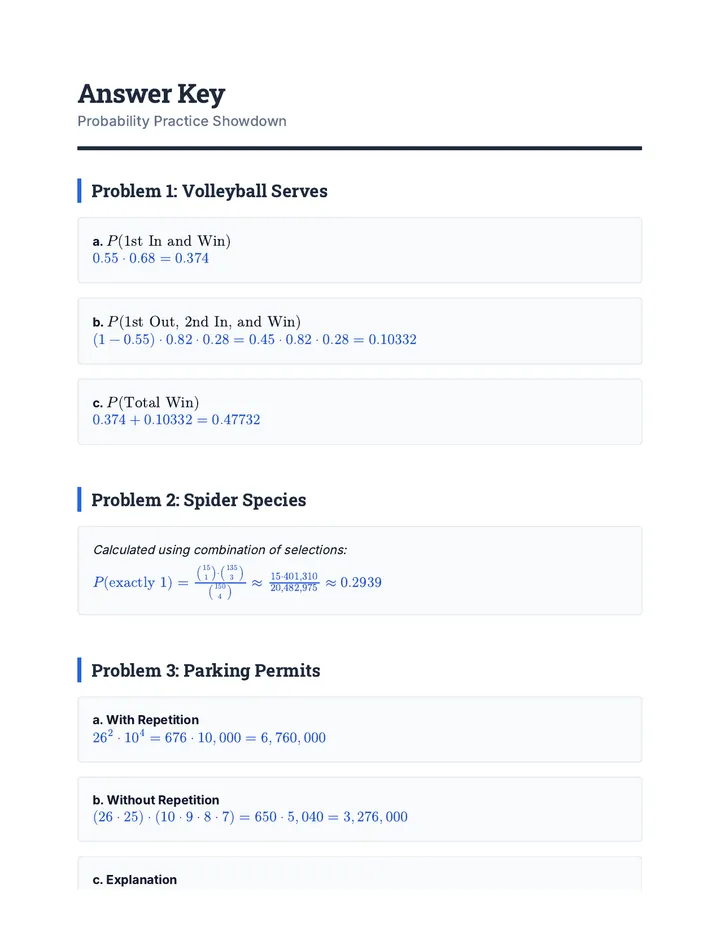
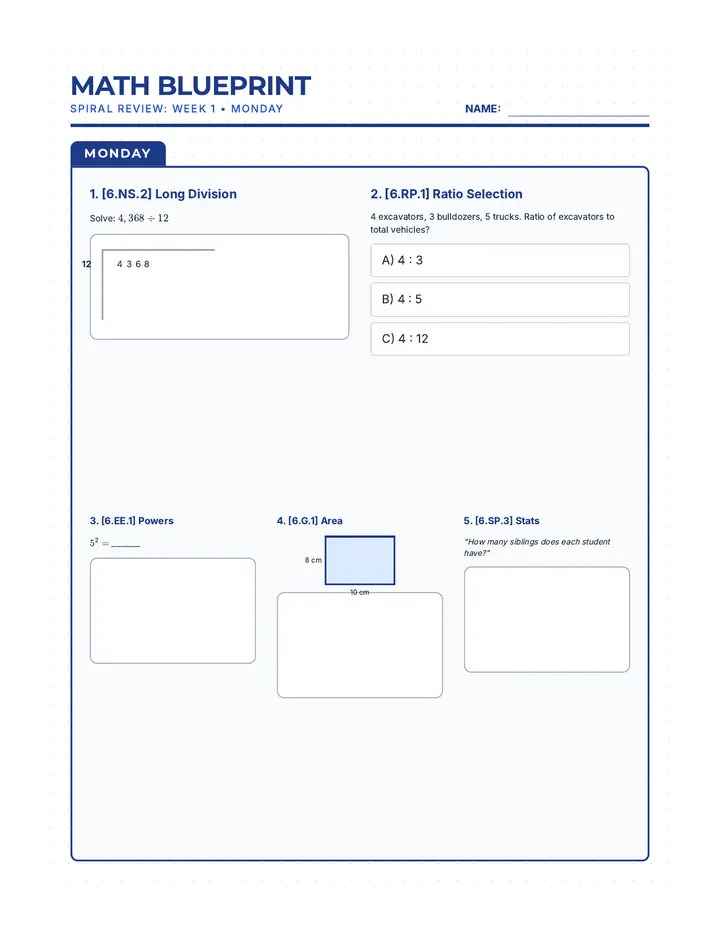
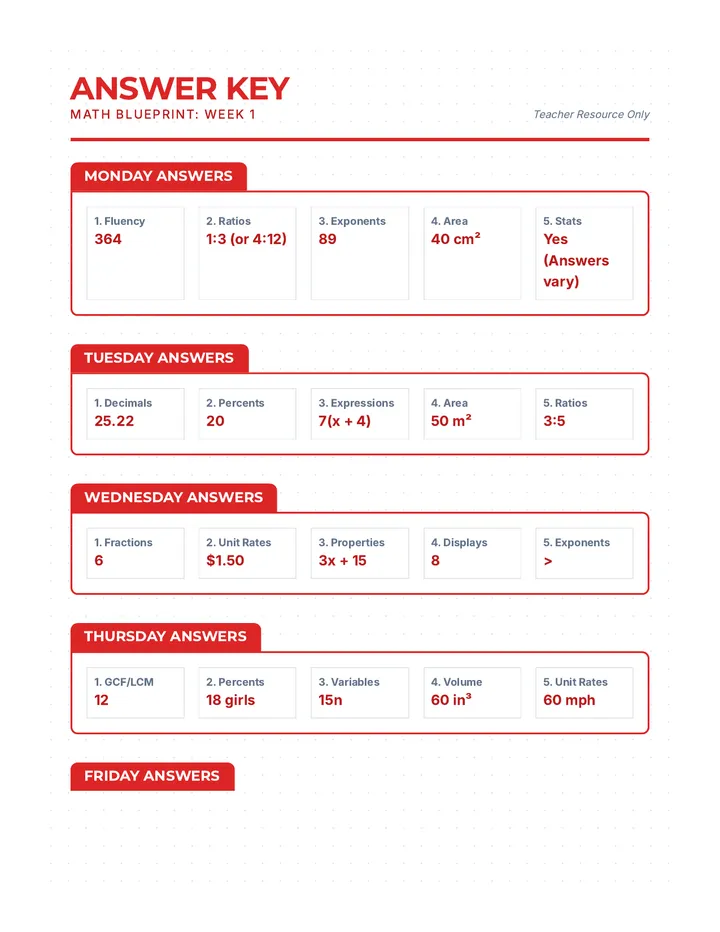
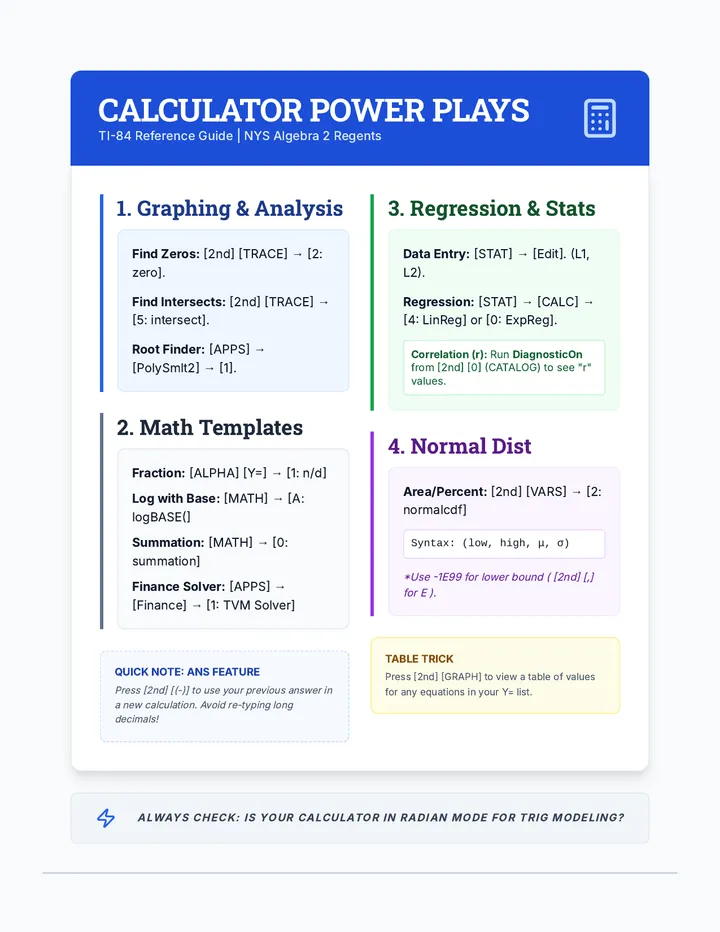
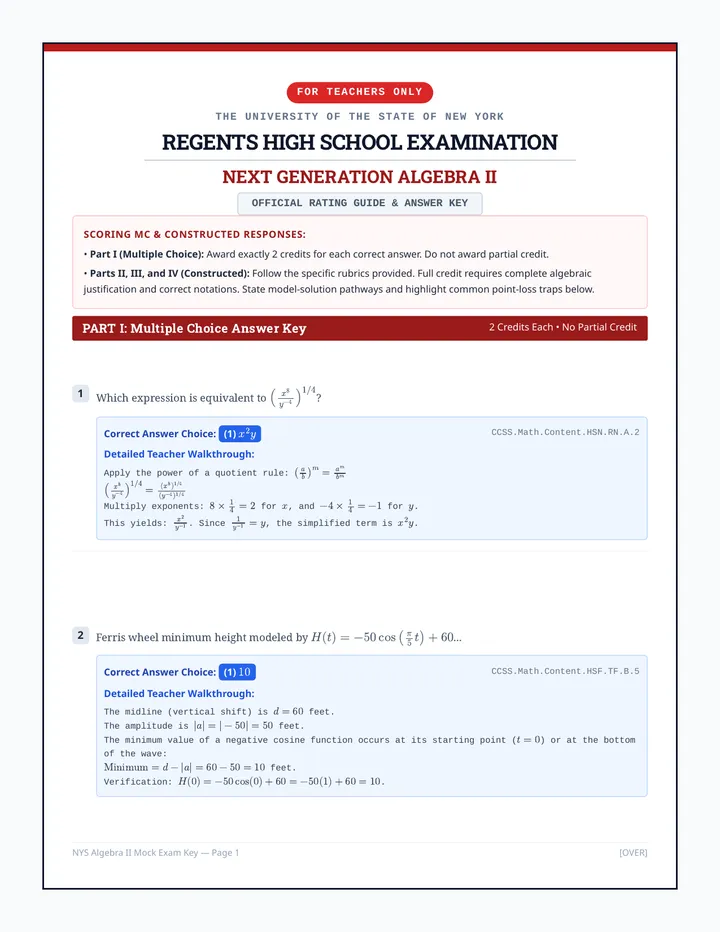
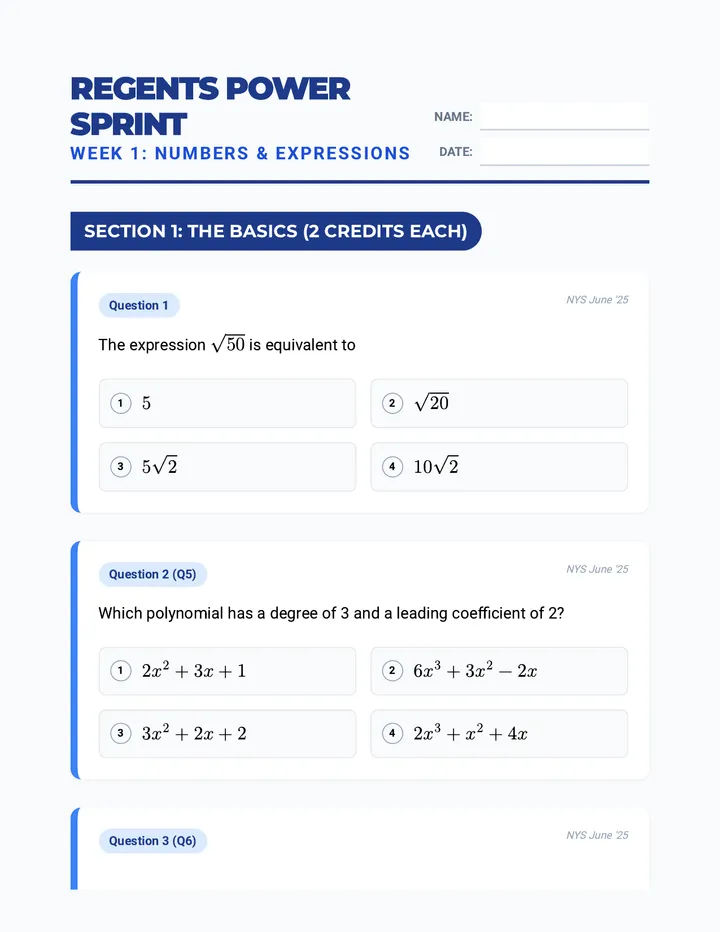
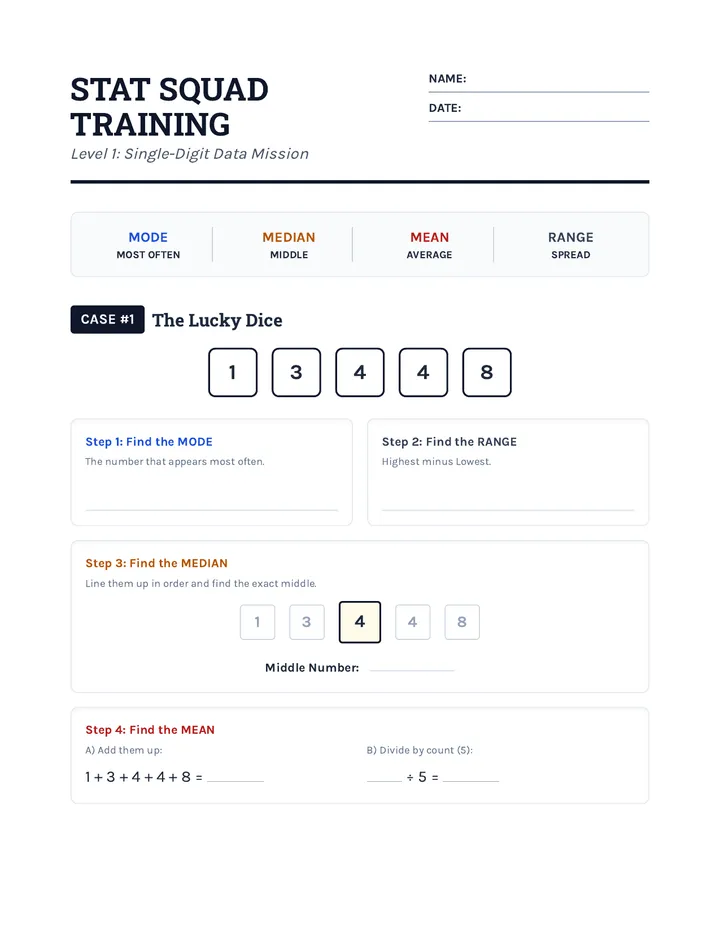
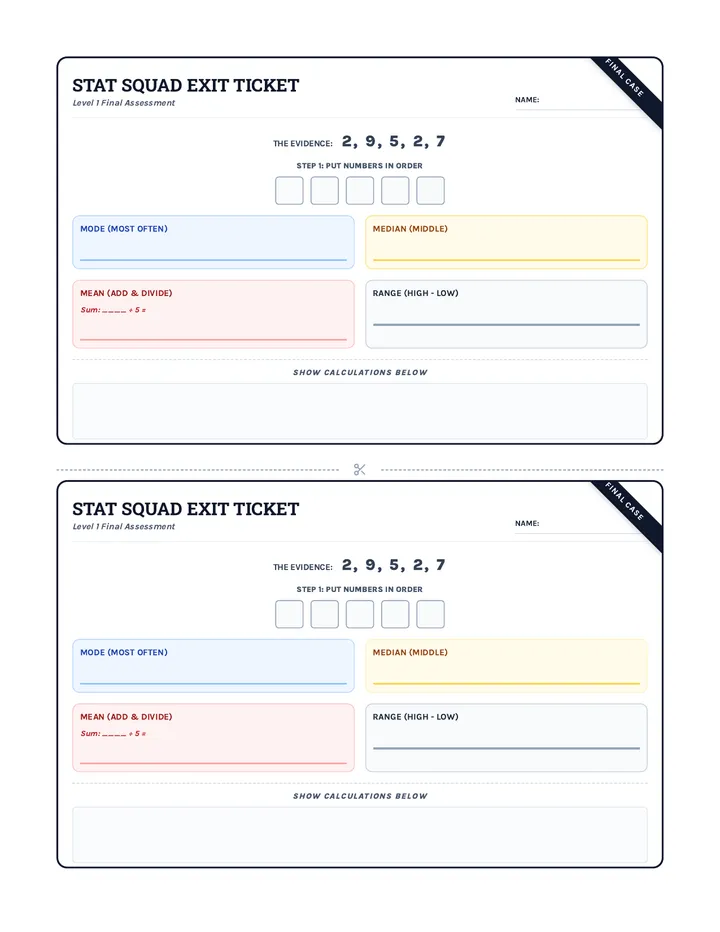
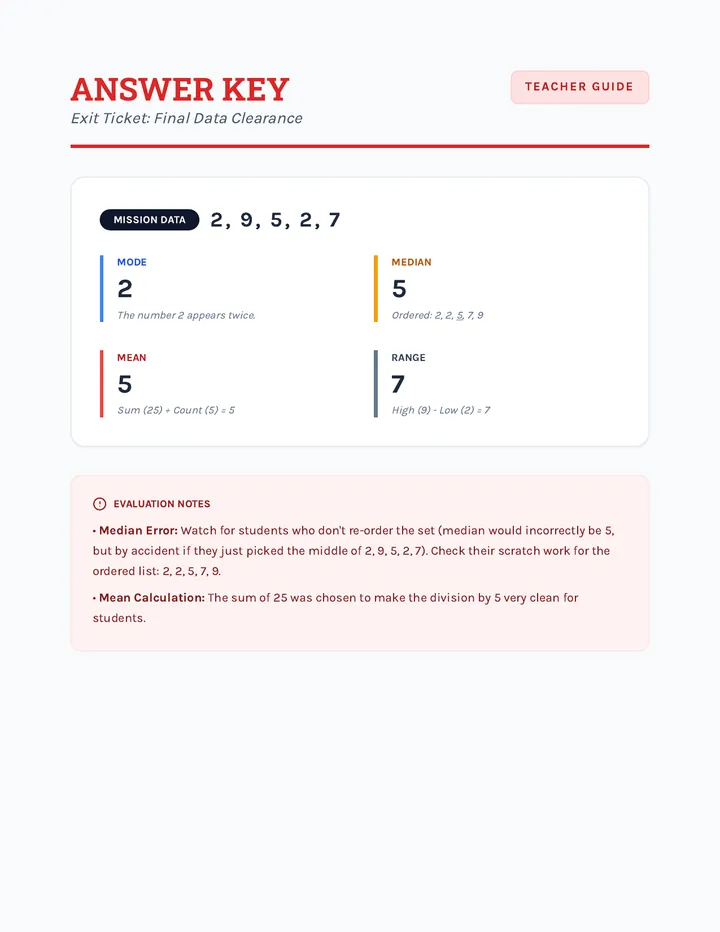
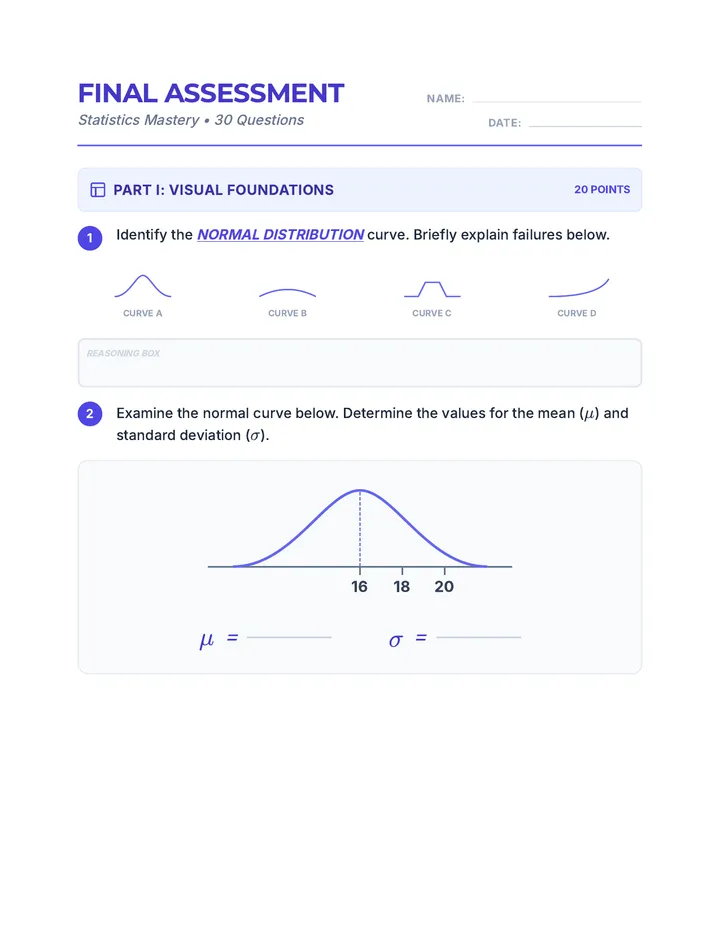
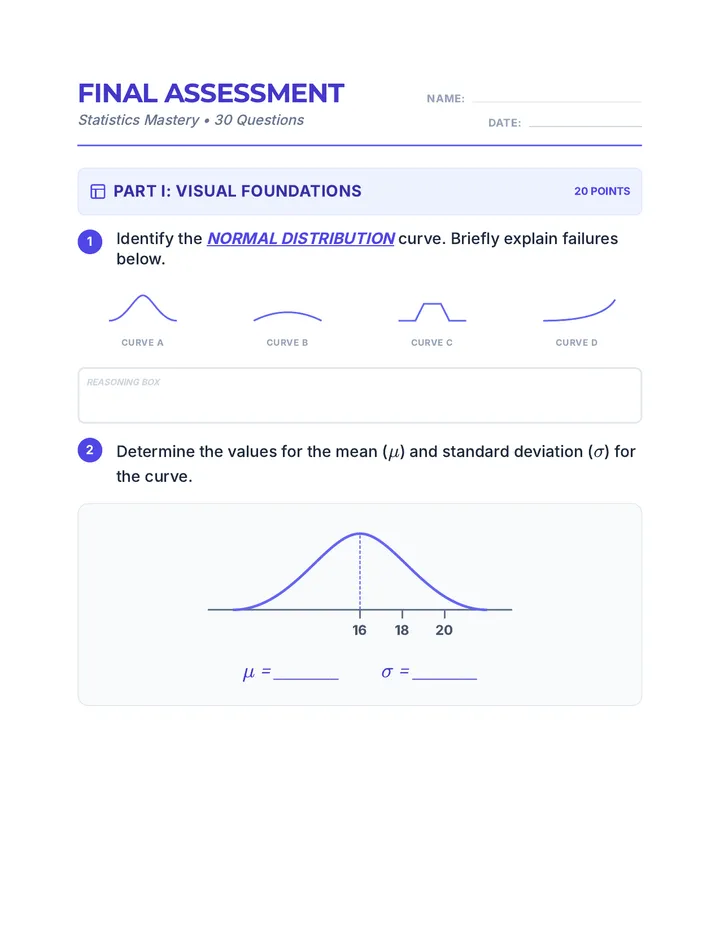
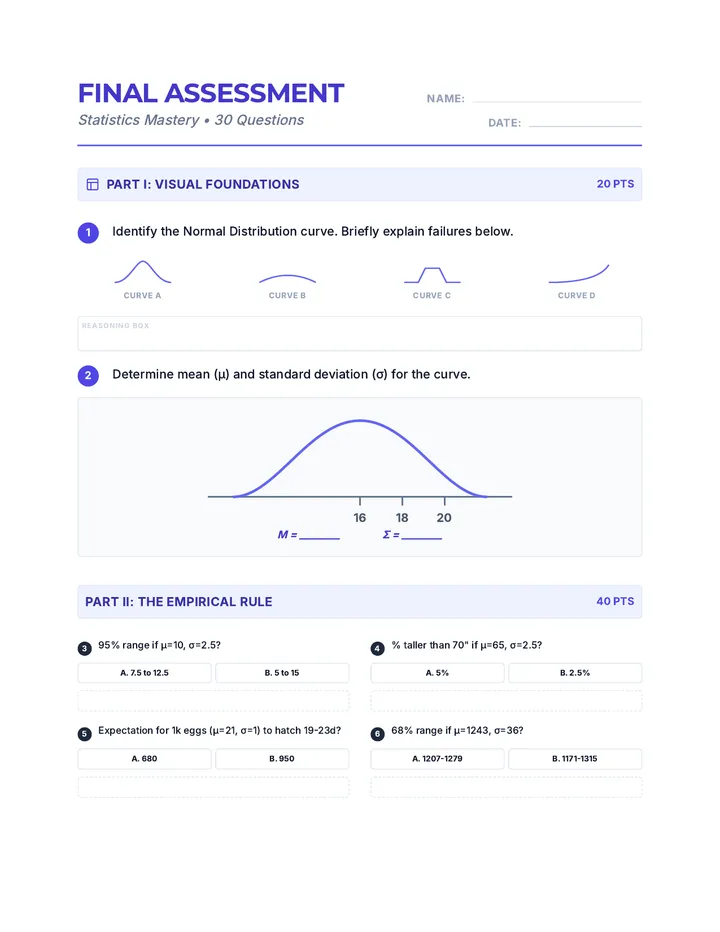
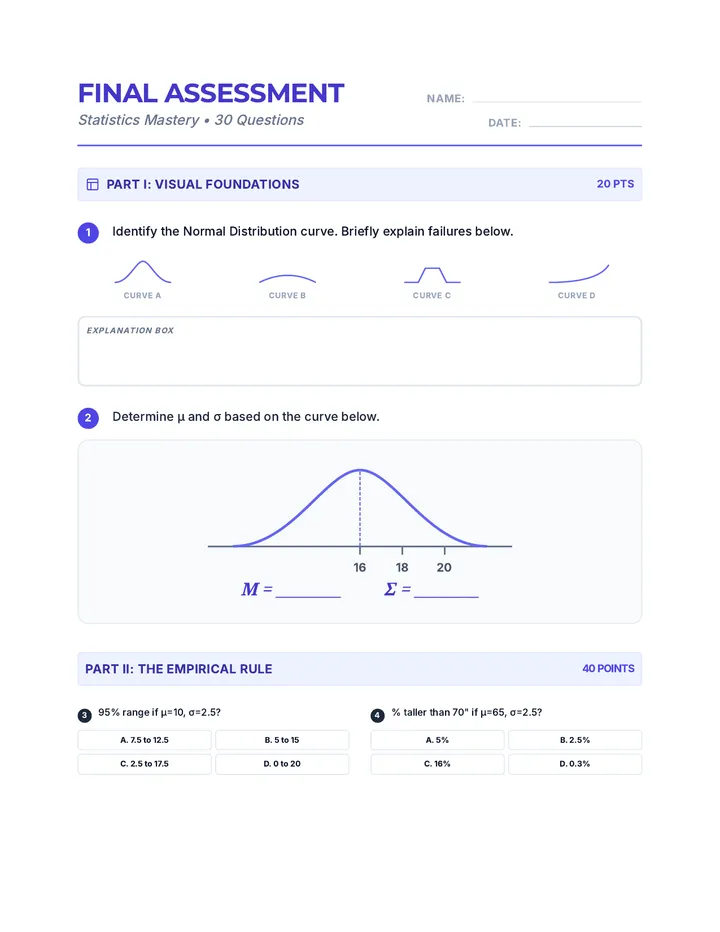
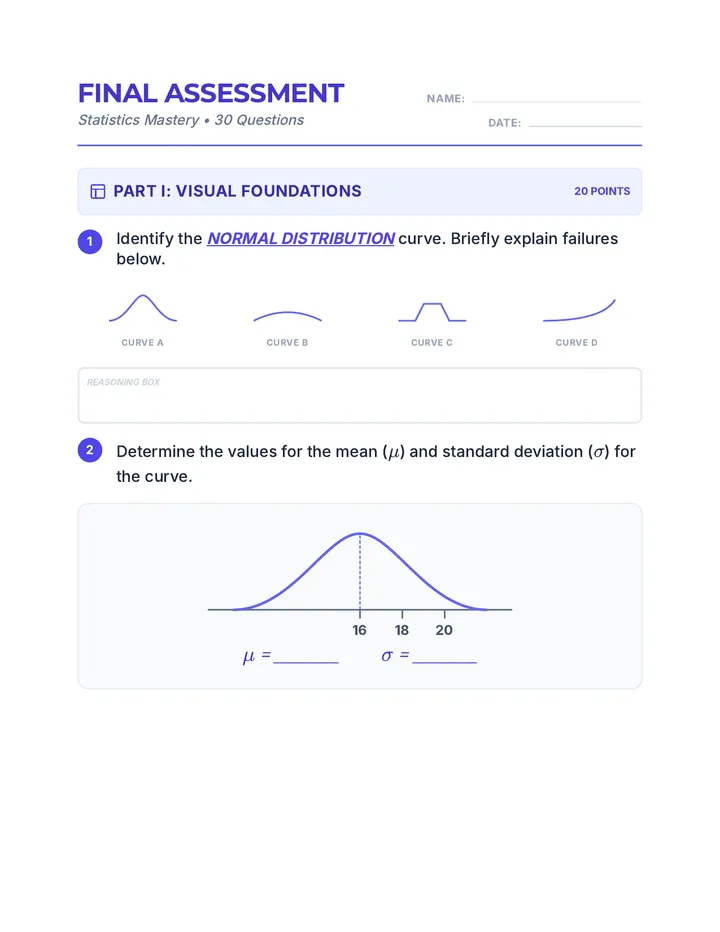
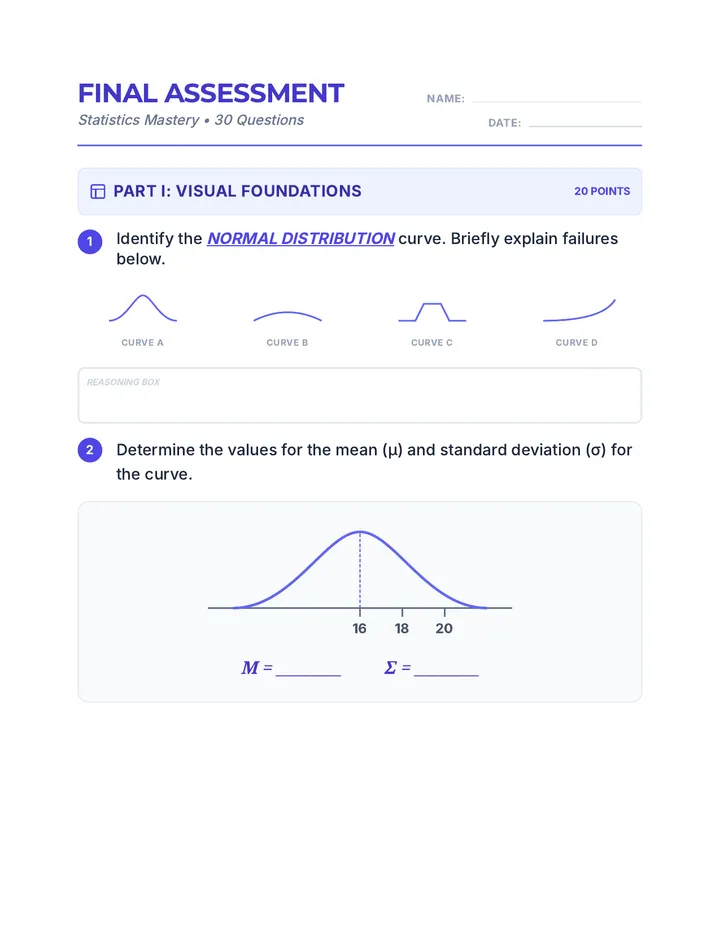
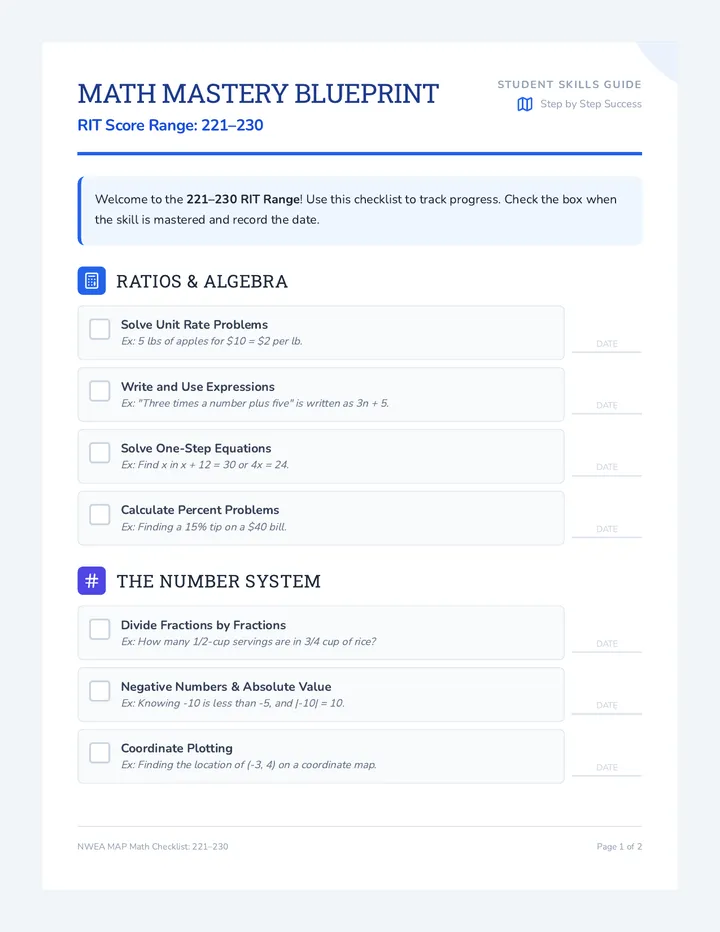
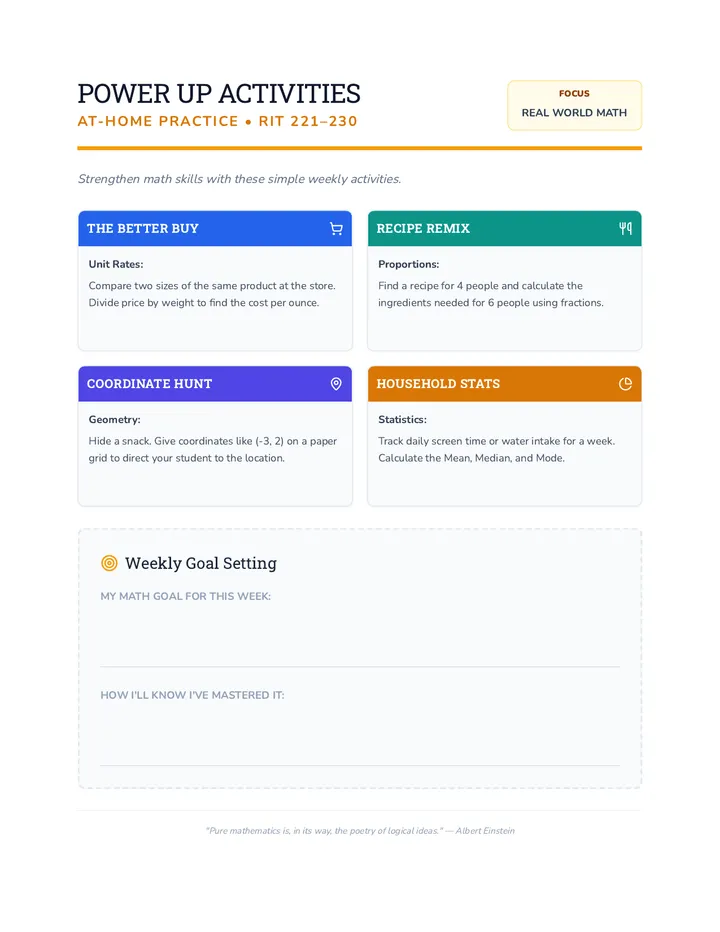
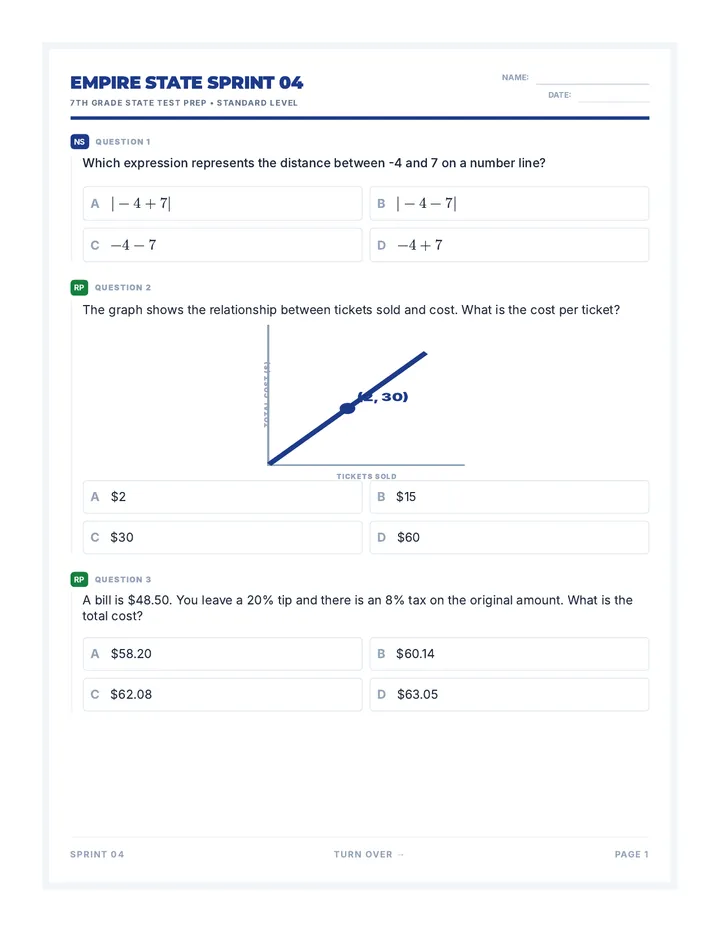
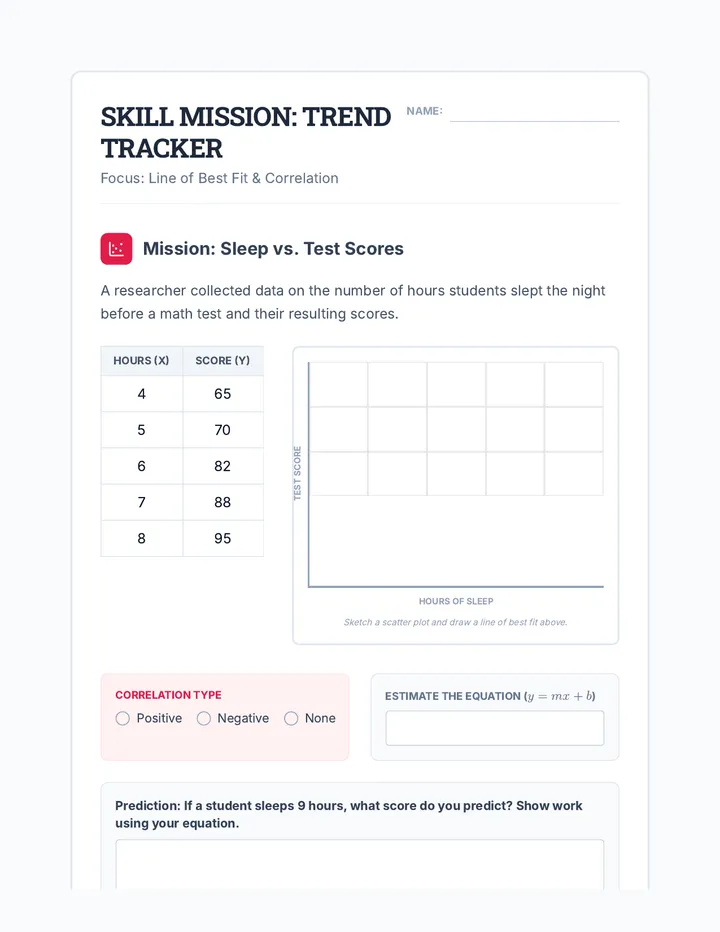
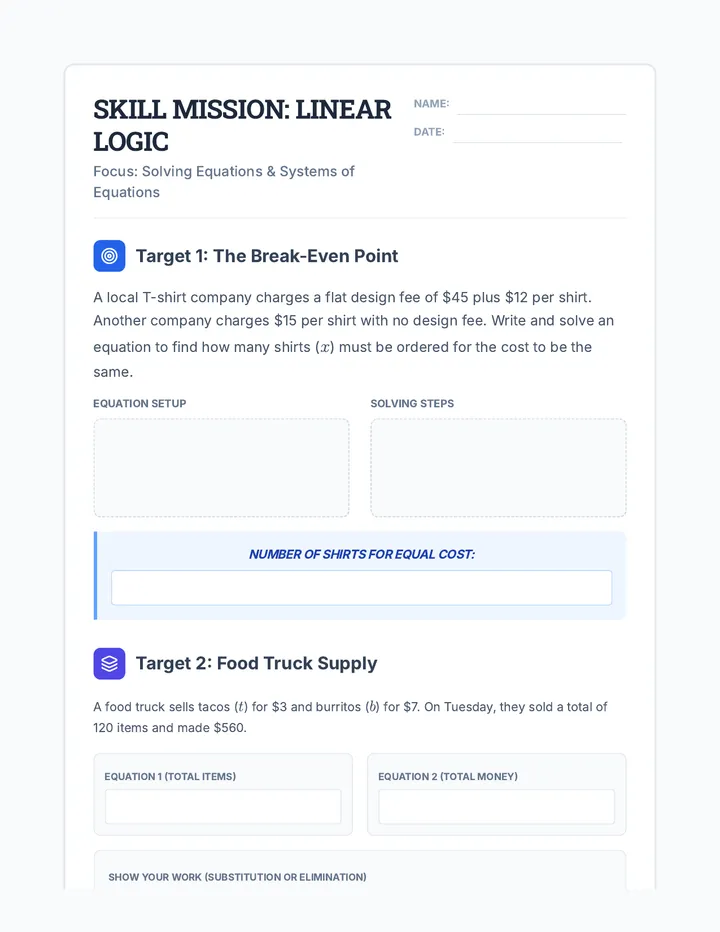
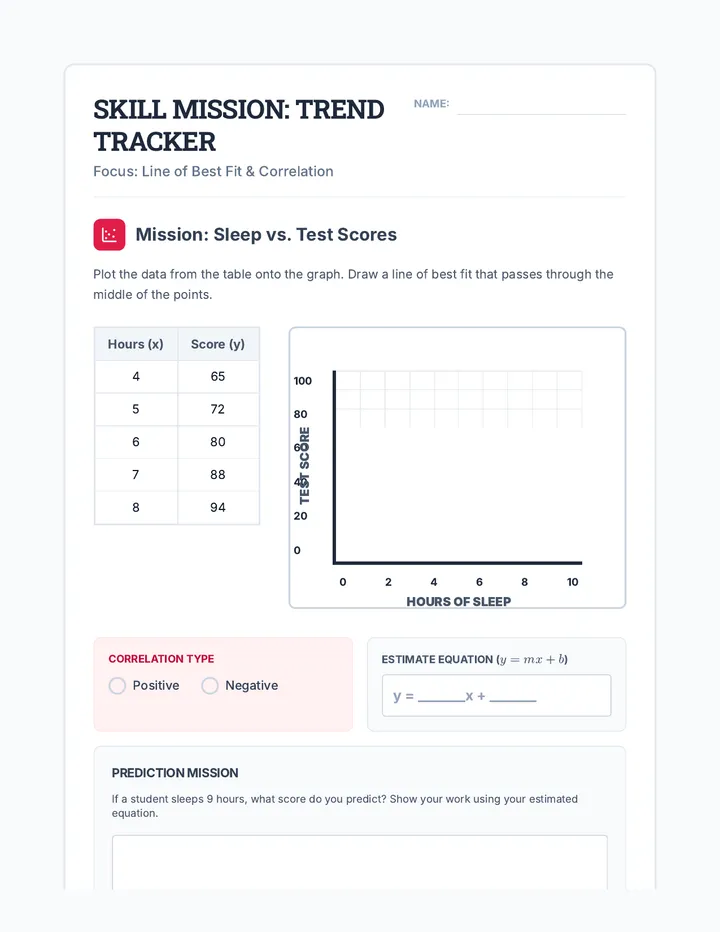
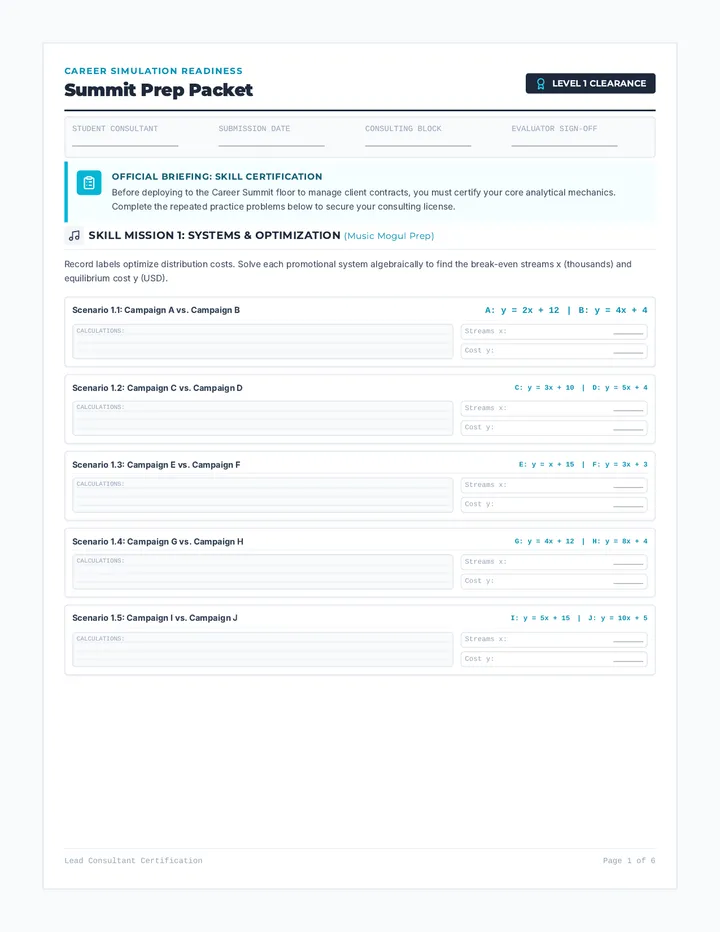
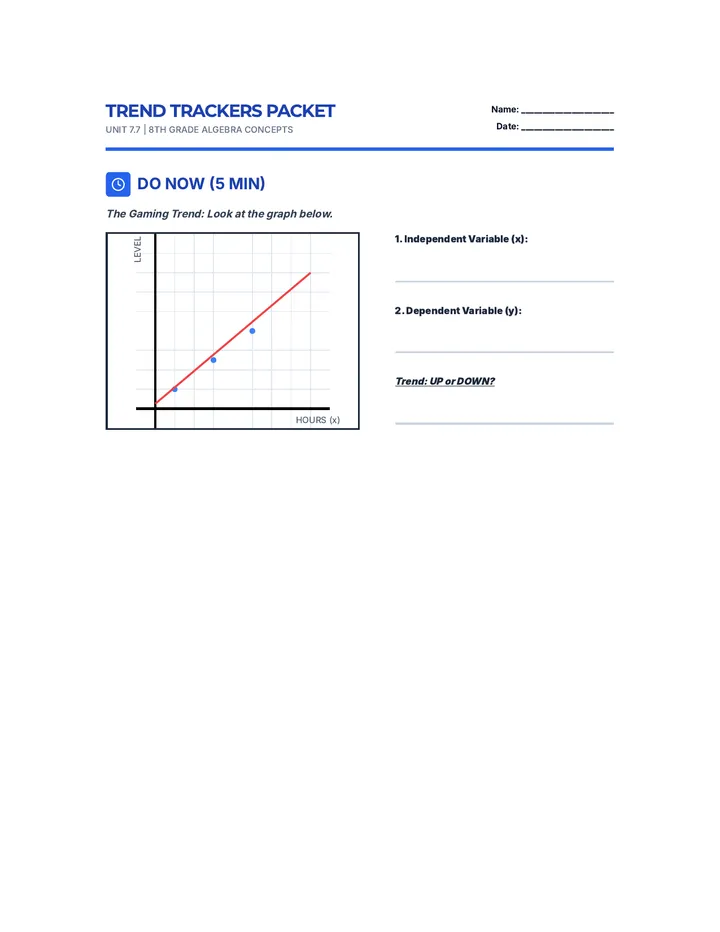
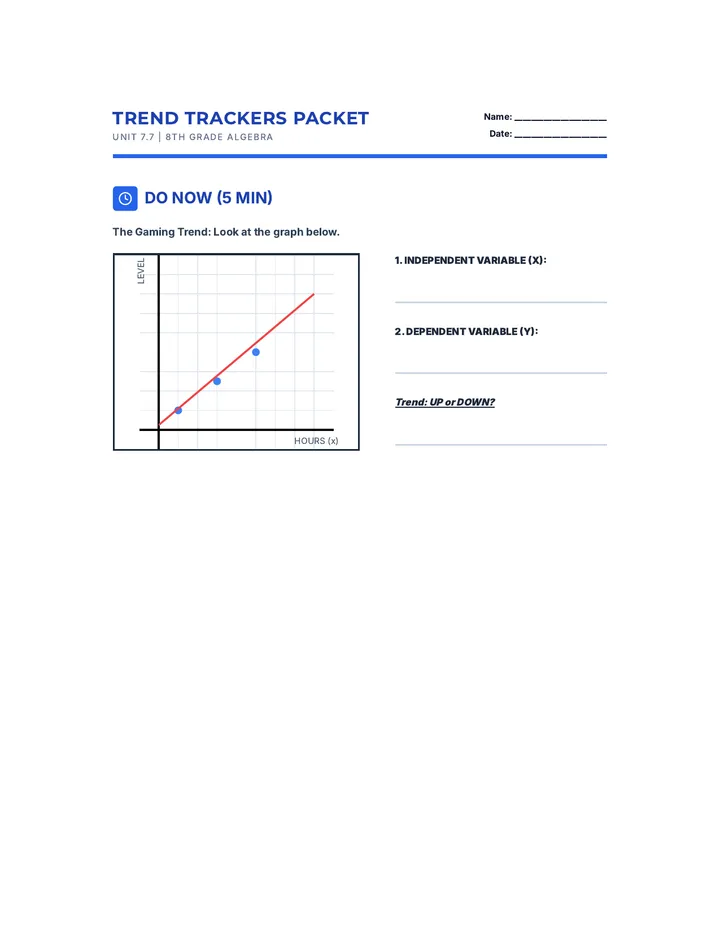
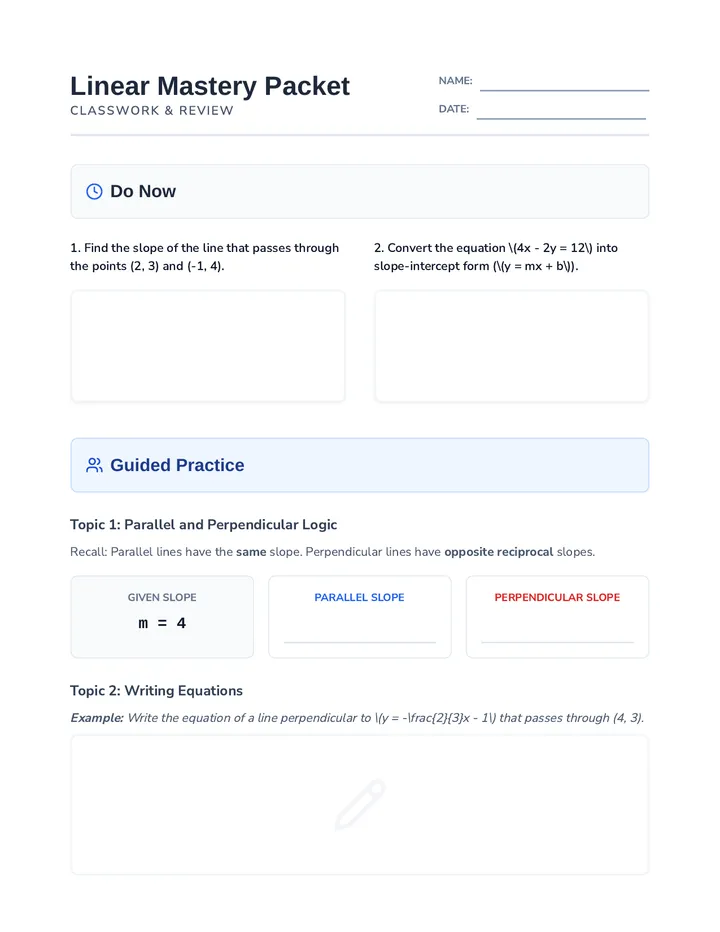
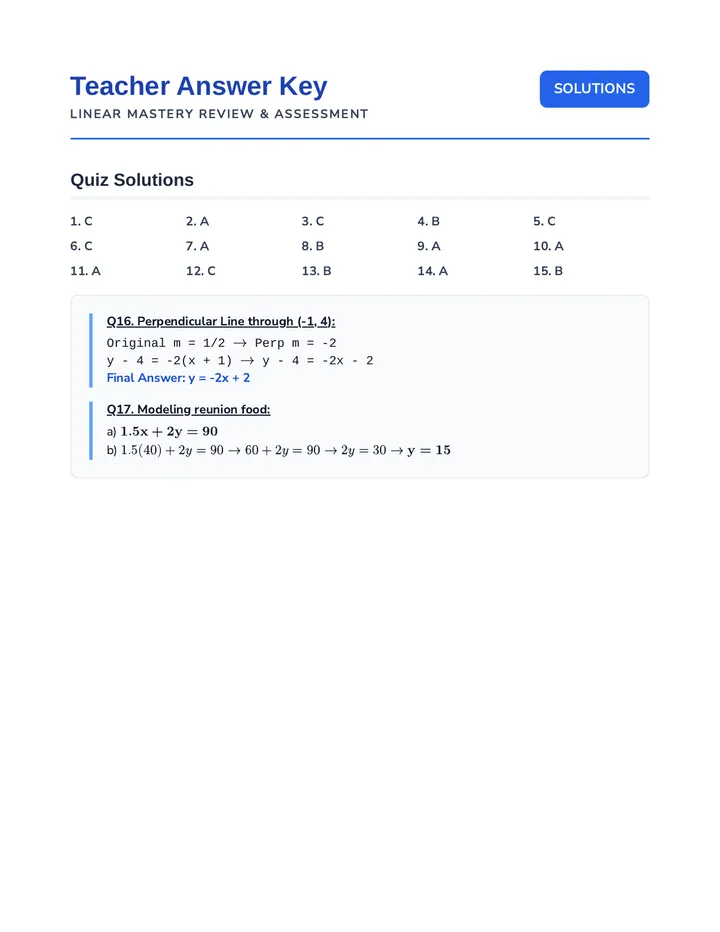
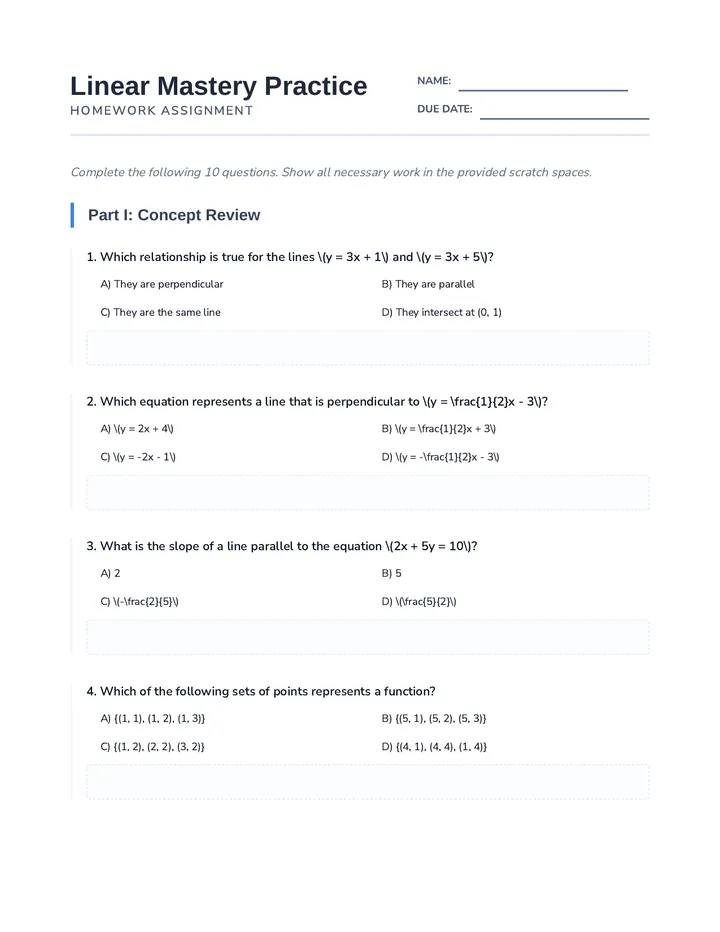
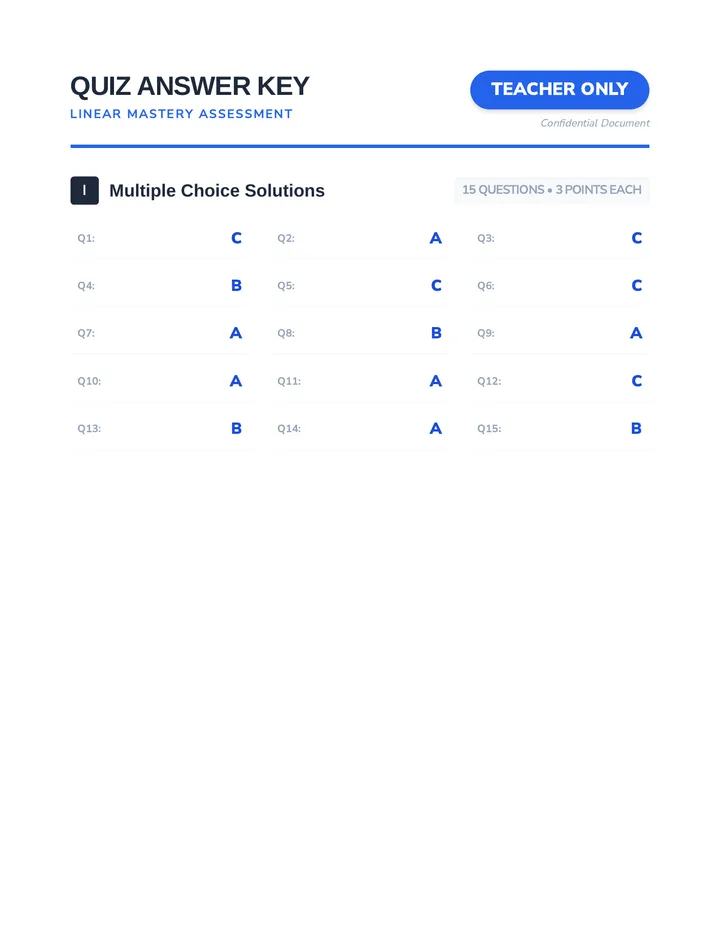
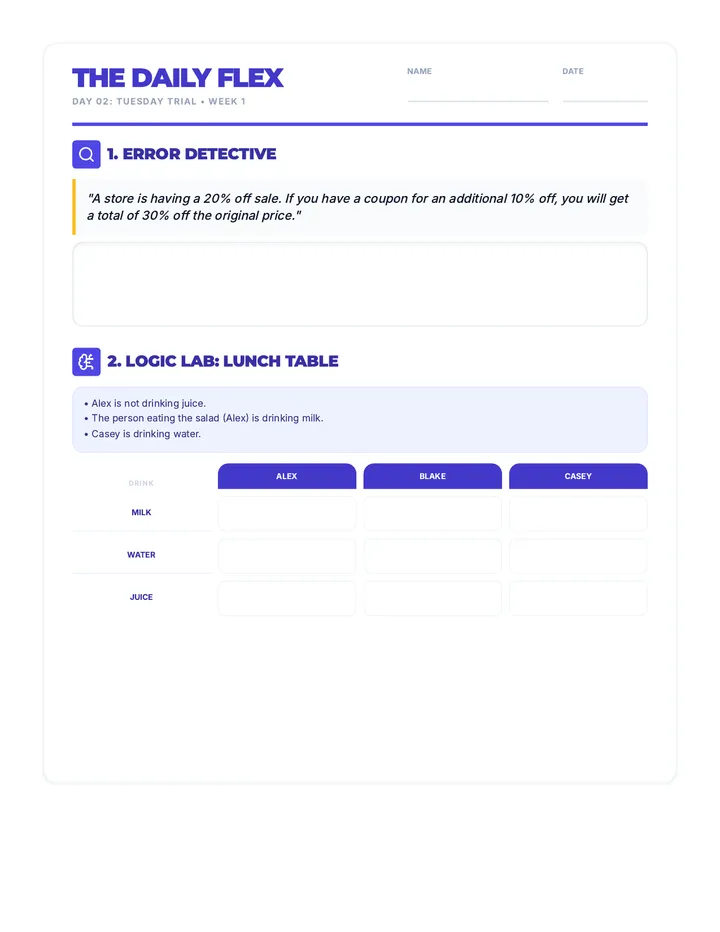
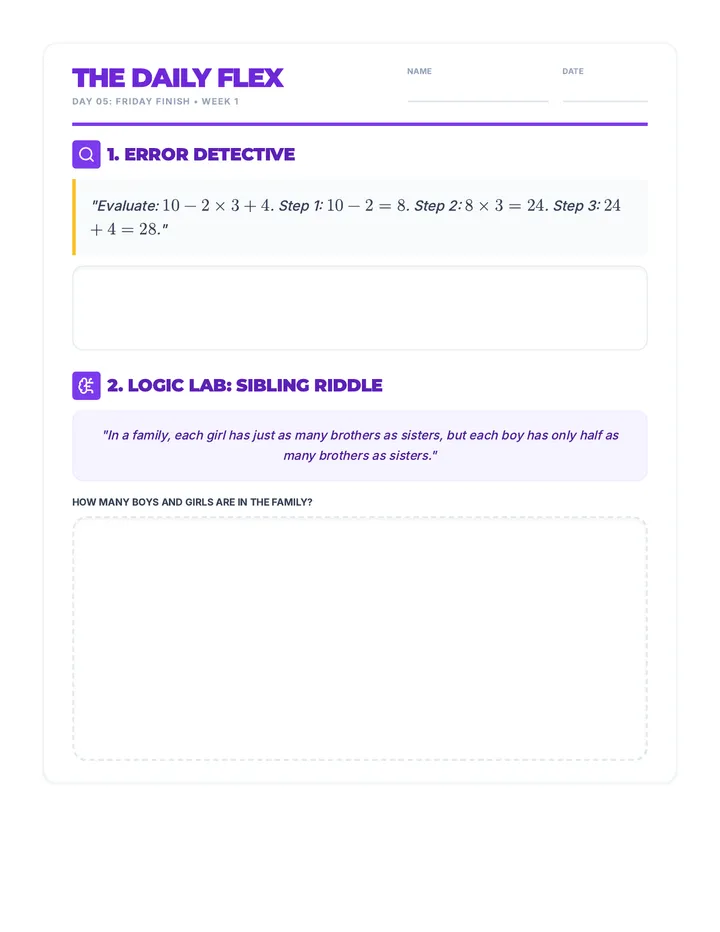
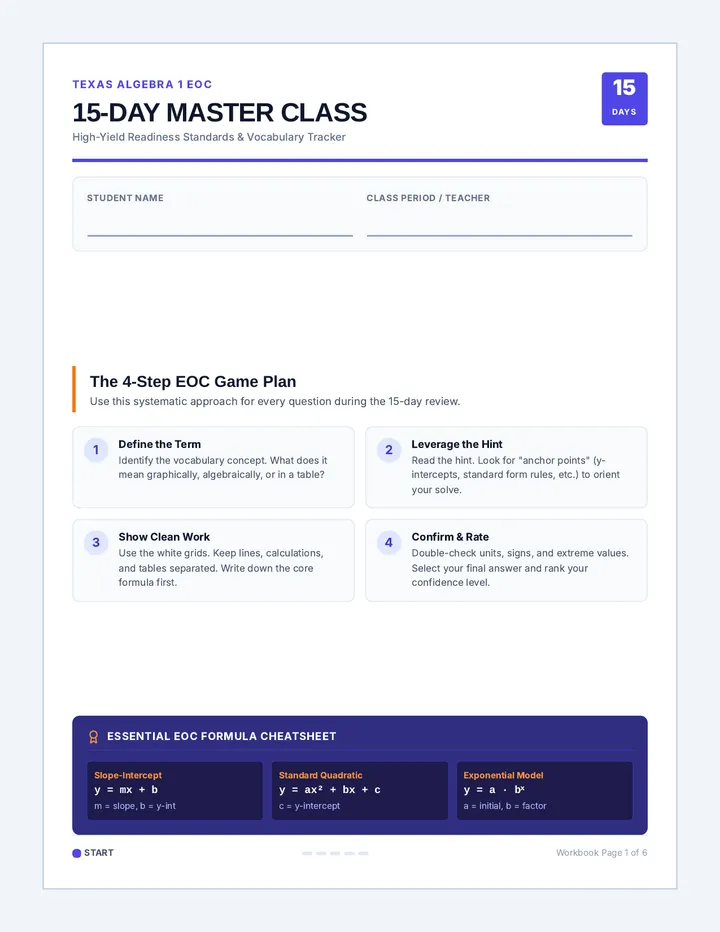
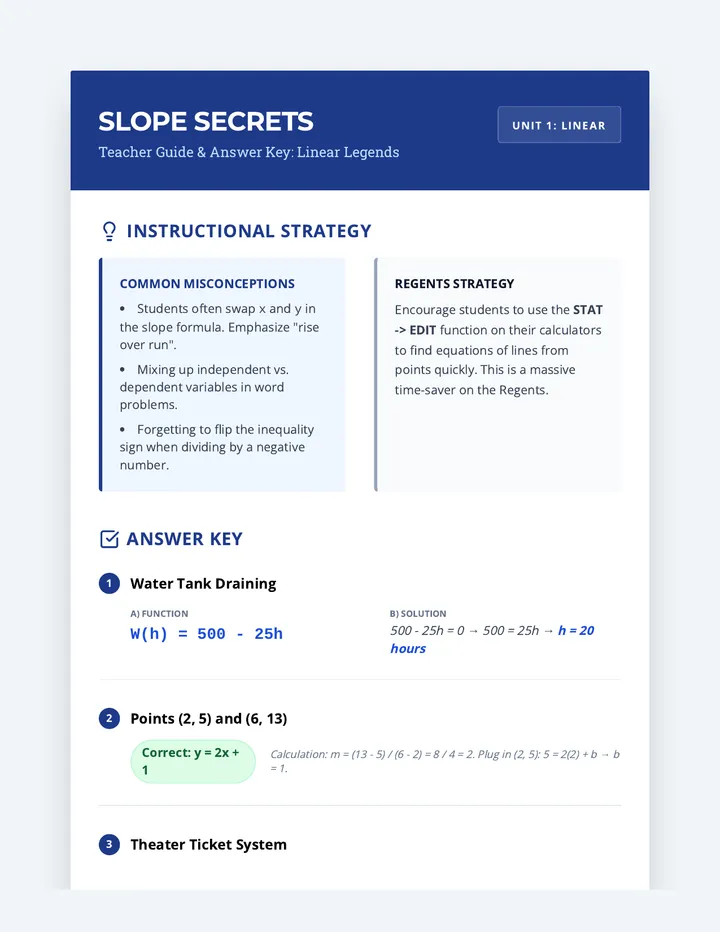
Statistics & Probability
Data representation, distributions, and statistical variability using sampling and inference techniques. Integrates probability models, compound events, bivariate patterns, and linear models to guide data-driven decision making.