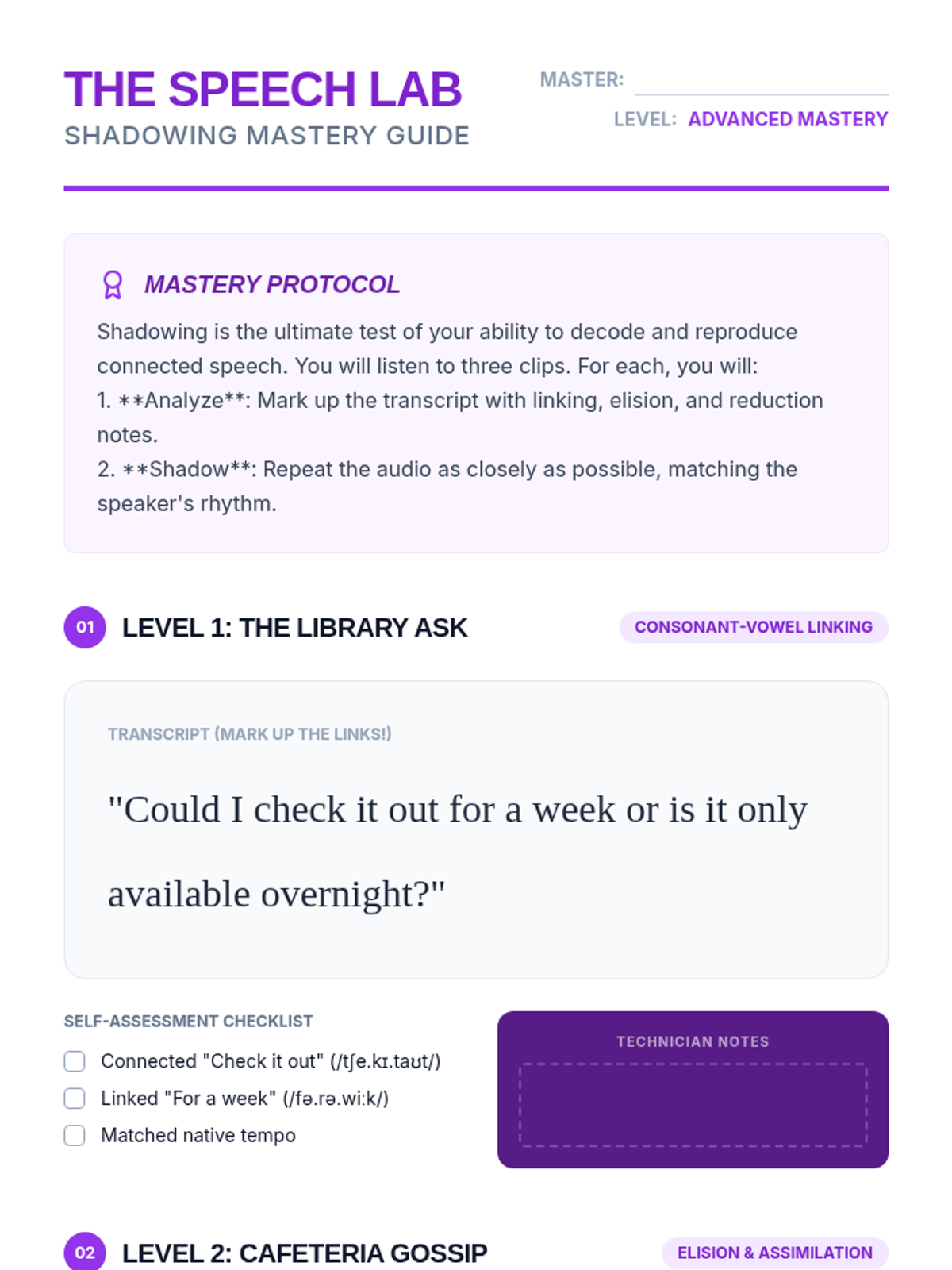
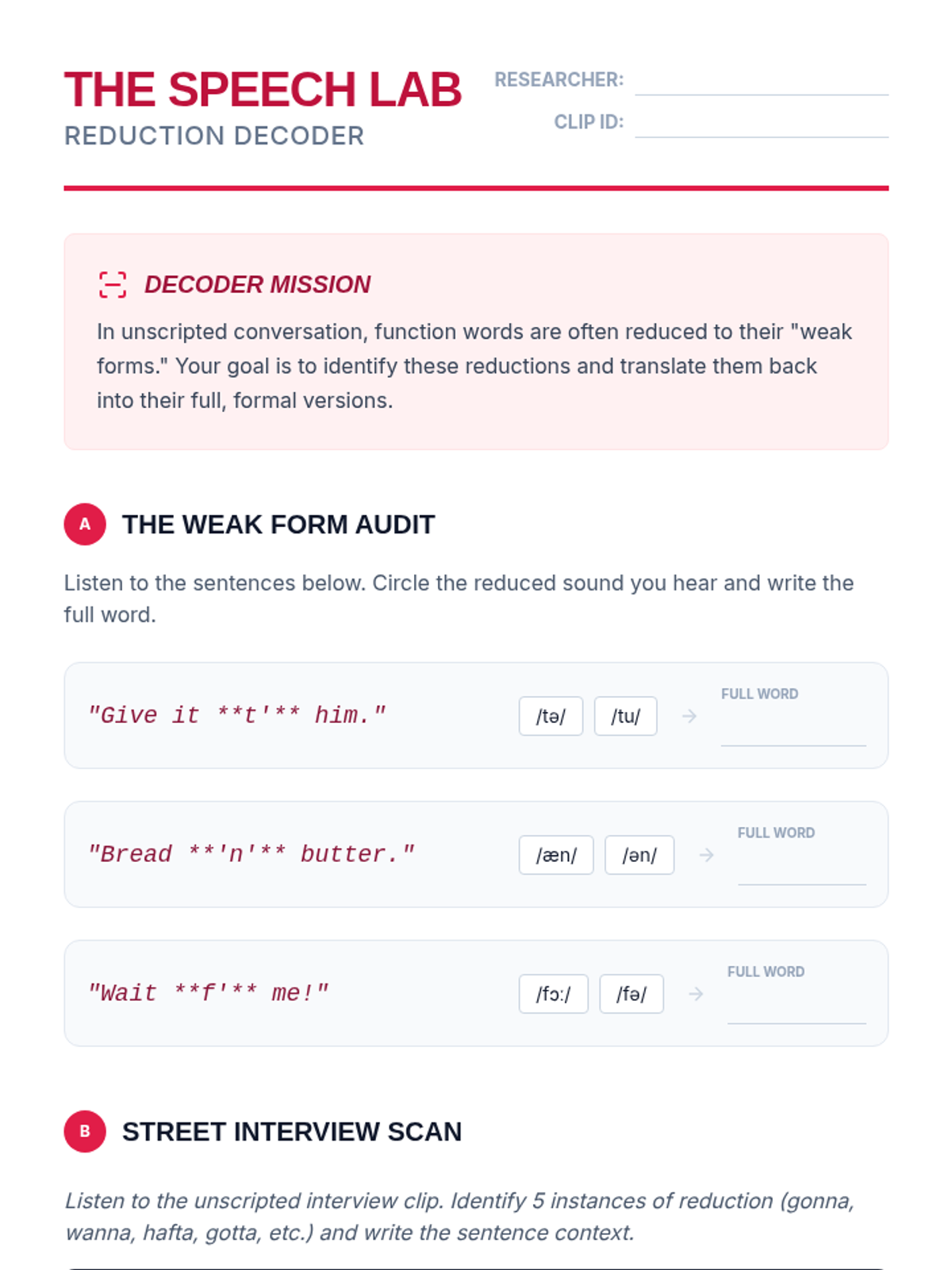
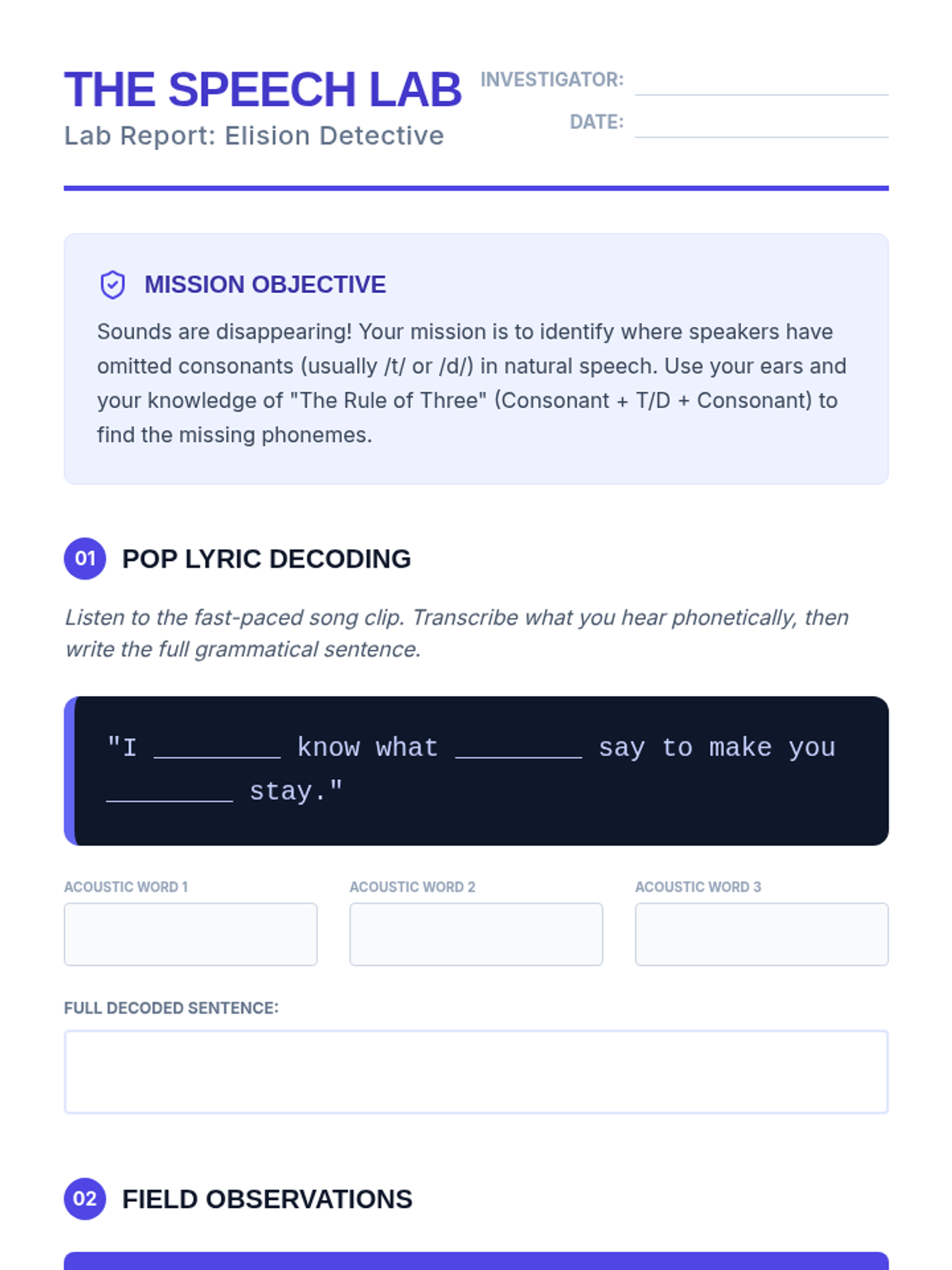
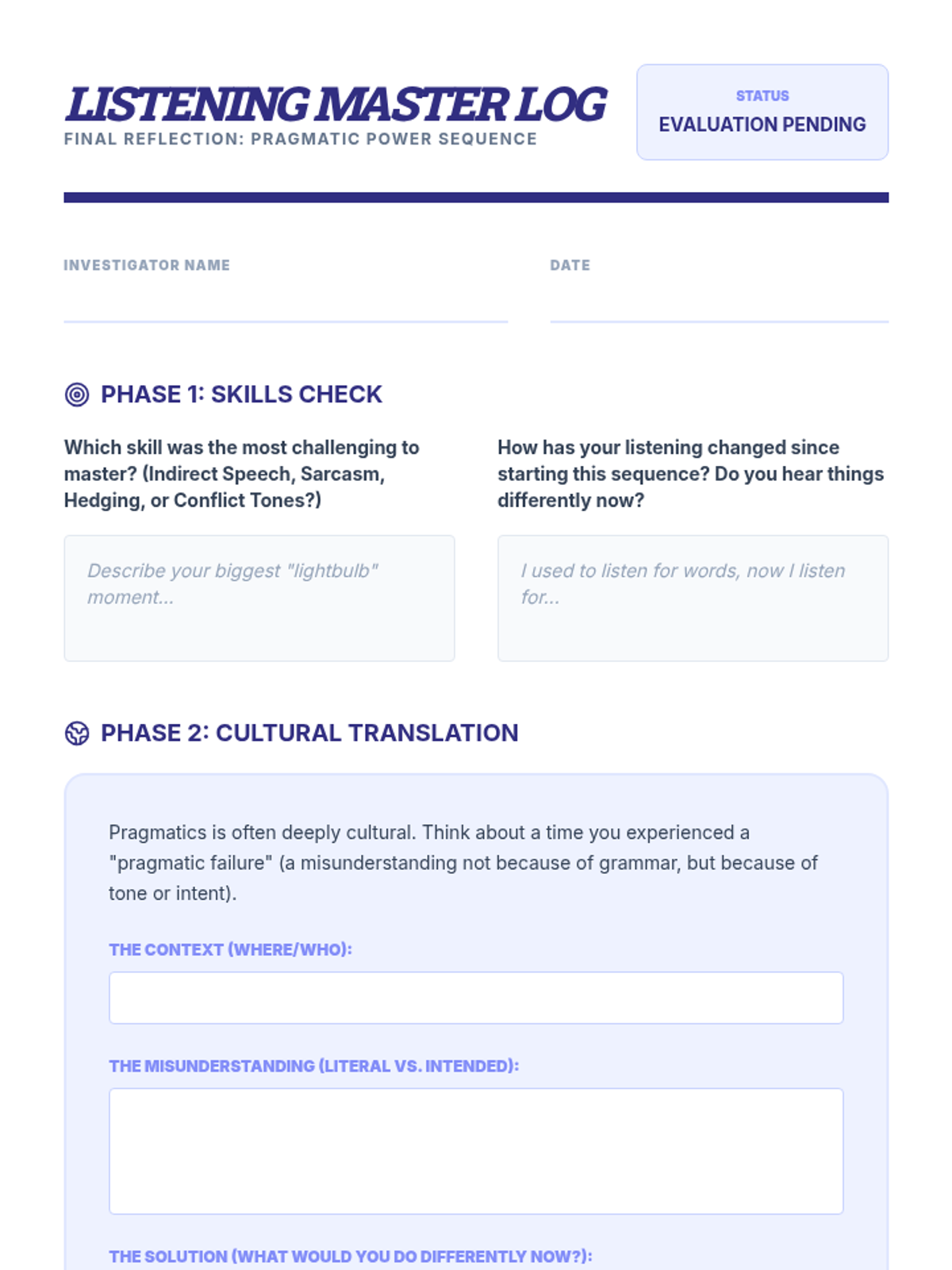
The final lesson applies all previous skills to a sustained narrative format. Students listen to a podcast episode, mapping the plot and identifying colloquial nuances to demonstrate comprehensive understanding.
The final lesson applies all previous skills to a sustained narrative format. Students listen to a podcast episode, mapping the plot and identifying colloquial nuances to demonstrate comprehensive understanding.