Data representation, distributions, and statistical variability using sampling and inference techniques. Integrates probability models, compound events, bivariate patterns, and linear models to guide data-driven decision making.
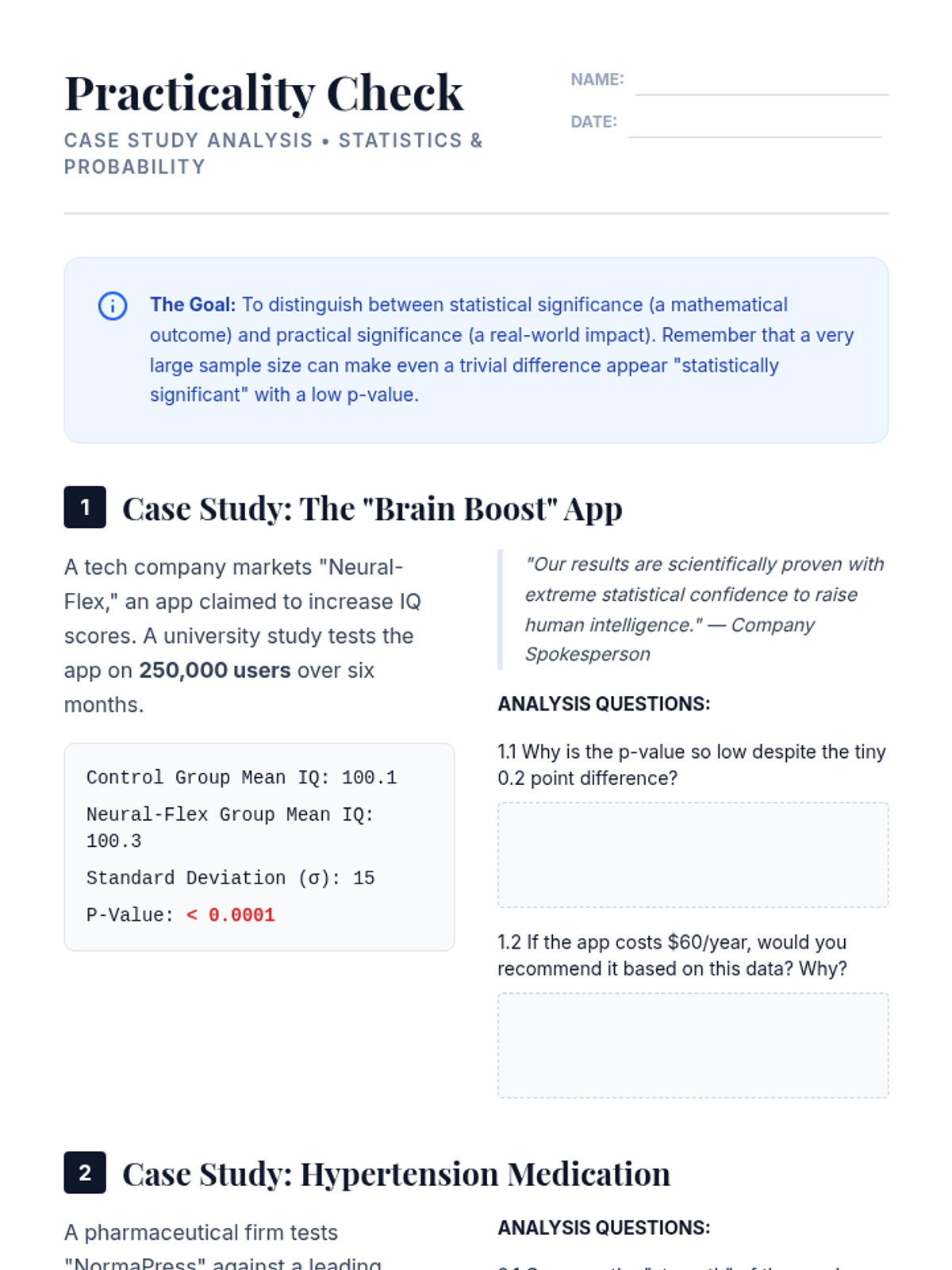
This advanced sequence for undergraduate students explores the critical distinction between statistical significance and practical importance. Students move beyond p-values to master effect size measures like Cohen's d and the principles of statistical power, culminating in a critical analysis of the replication crisis and the role of rigorous study design in scientific integrity.
An advanced graduate-level module on statistical sampling techniques focusing on the mathematical correction of data after collection. Topics include probability weights, non-response adjustment through raking, imputation of missing values, and computational variance estimation via Bootstrap and Jackknife methods.
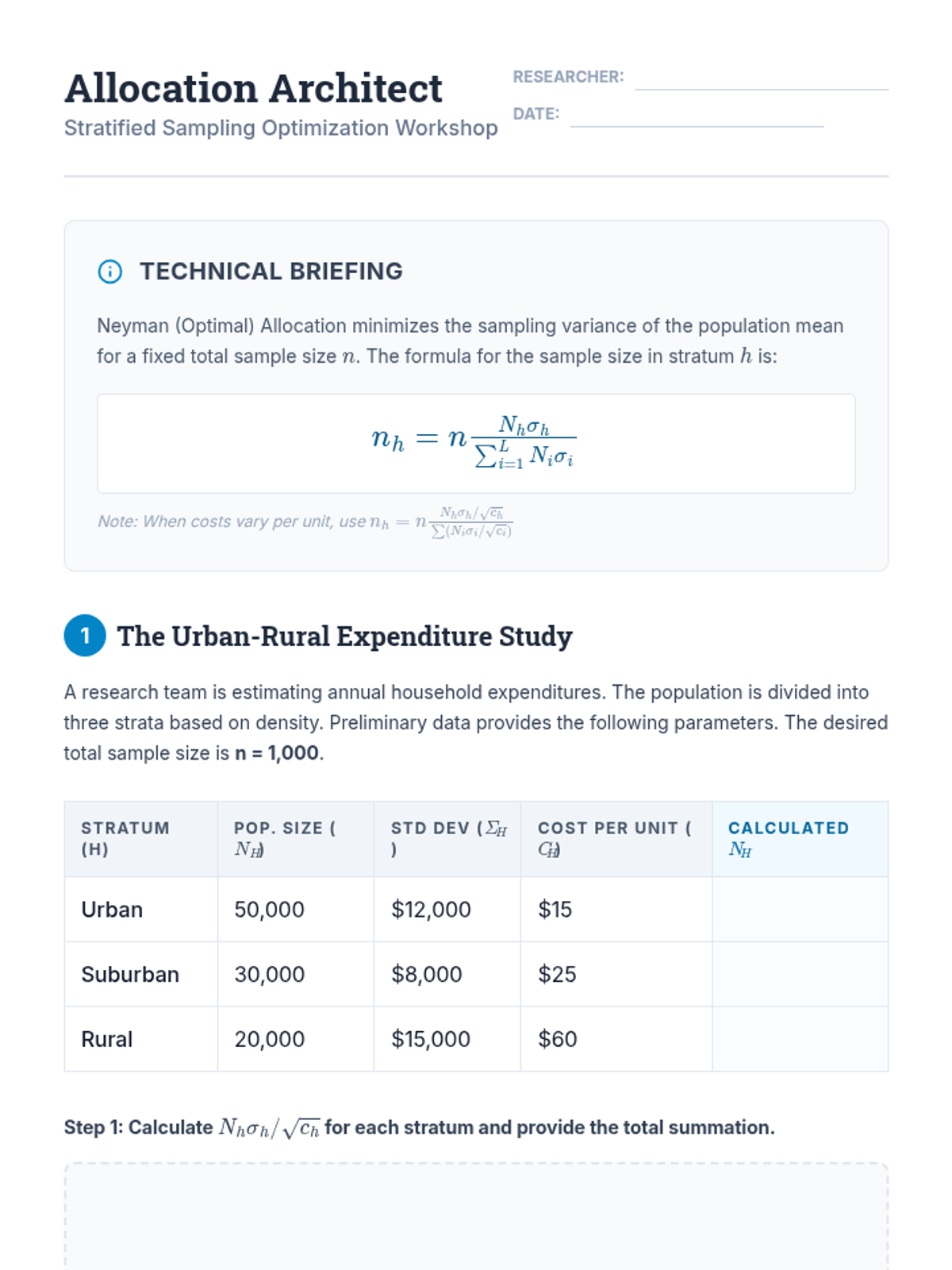
This graduate-level sequence covers advanced statistical sampling techniques, focusing on the optimization of stratified, cluster, and multi-stage designs. Students learn to navigate the trade-offs between precision and cost, calculate design effects, and mitigate biases like periodicity.
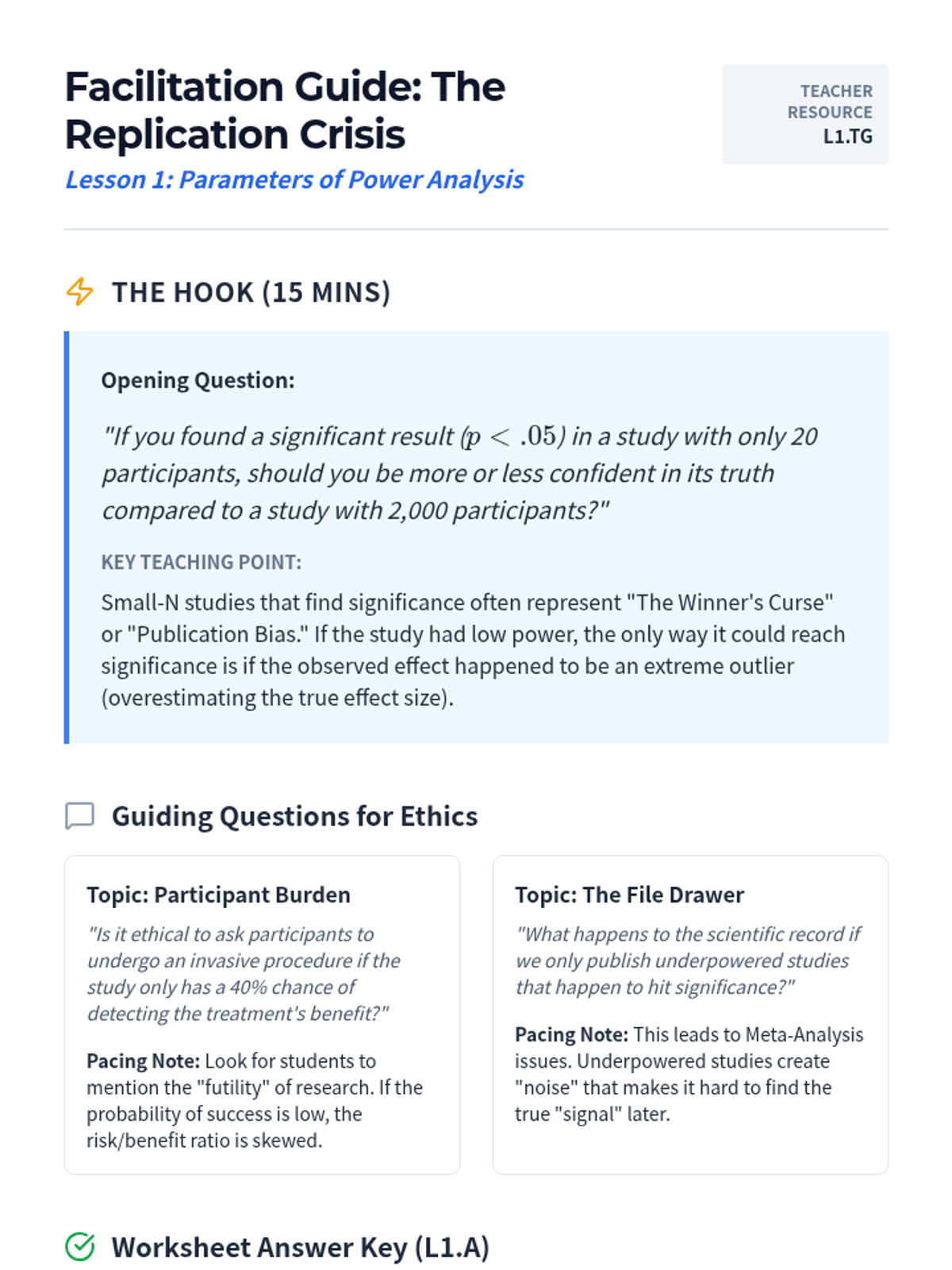
This graduate-level sequence covers the theoretical foundations and practical applications of power analysis. Students will learn to determine necessary sample sizes for various statistical models, conduct sensitivity analyses, and write robust justifications for research protocols.
A rigorous graduate-level examination of probability sampling theory, focusing on the mathematical properties of estimators, the mechanics of selection bias, and the use of Monte Carlo simulations to validate sampling designs. Students explore simple random sampling, sampling frame errors, and the 'Big Data Paradox' through proofs and simulation logic.
A graduate-level sequence exploring computational resampling methods (Bootstrap, Jackknife, Permutation) to estimate the variability and uncertainty of dispersion statistics when parametric assumptions fail.
This sequence bridges the gap between theoretical probability and practical data science applications through rigorous statistical inference. Students explore sampling distributions and the Central Limit Theorem before diving into parametric and non-parametric hypothesis testing, culminating in experimental design and Bayesian fundamentals.
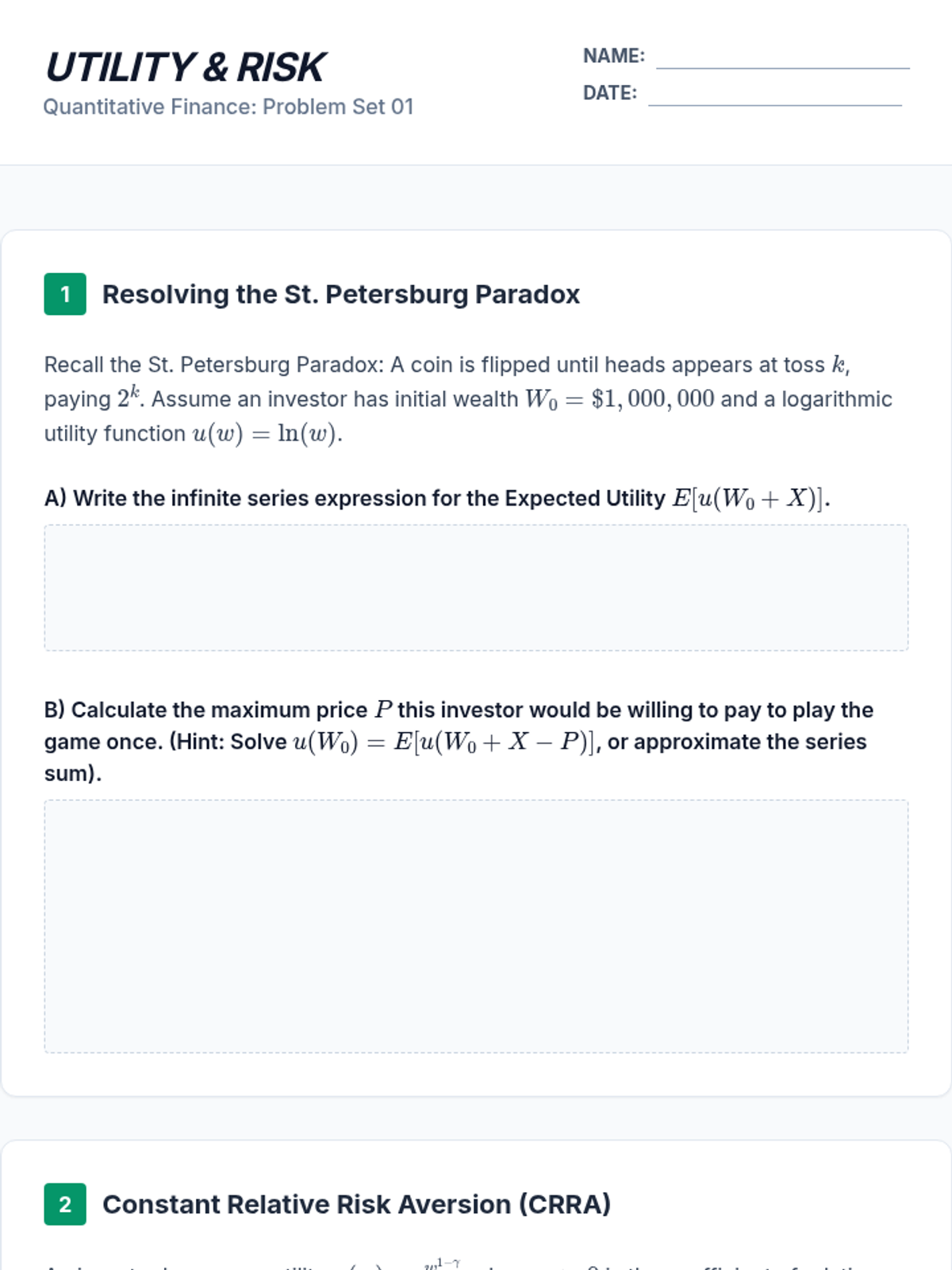
A graduate-level exploration of expected value applications in finance, covering utility theory, portfolio optimization, risk-neutral pricing, and tail risk metrics. Students transition from theoretical foundations to computational implementation using Monte Carlo methods.
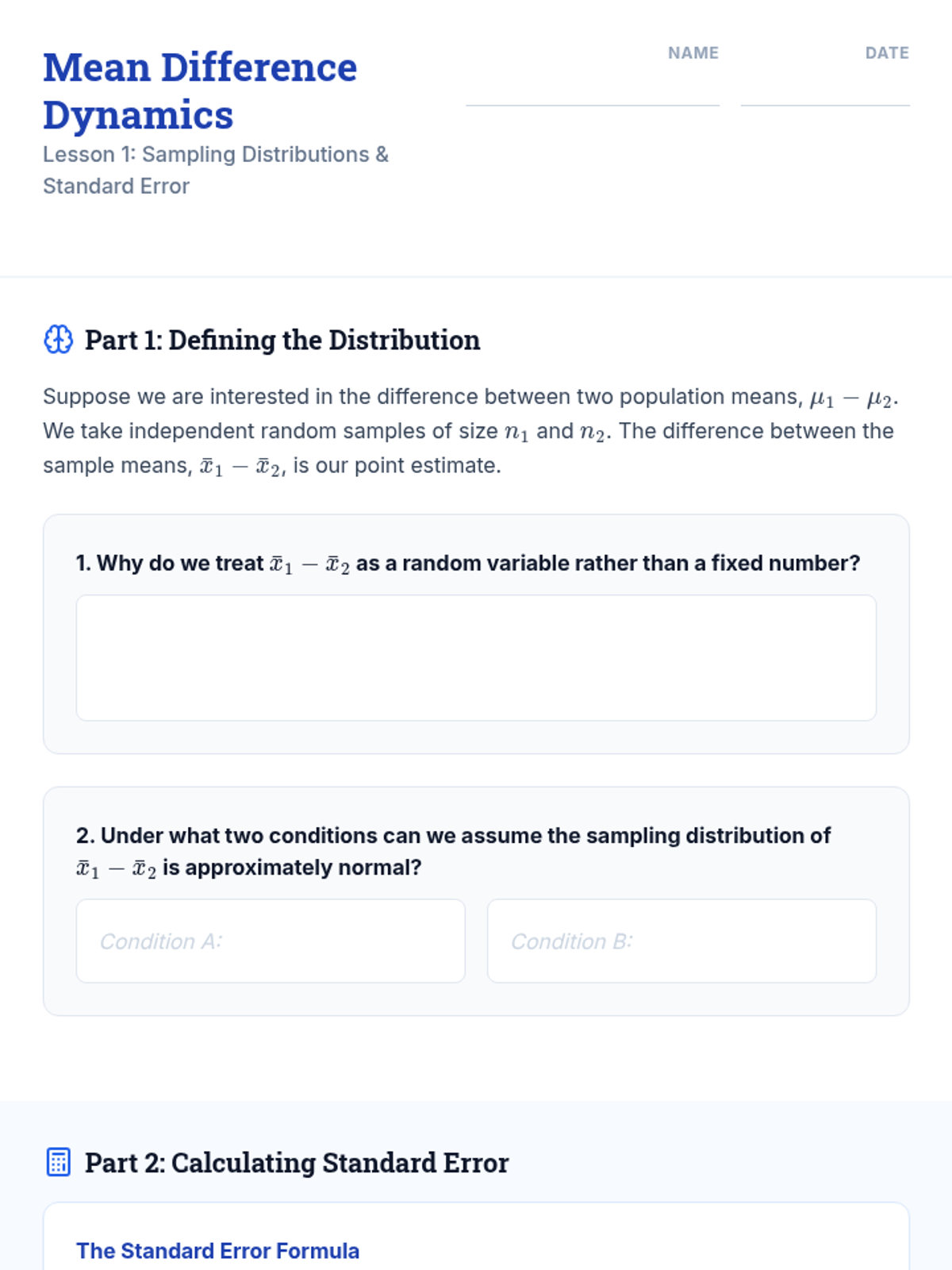
This sequence covers the theoretical and practical application of comparing means between two independent groups. Students progress from understanding sampling distributions and standard errors to performing pooled and unpooled t-tests, constructing confidence intervals, and verifying statistical assumptions using diagnostic tools.
A graduate-level sequence exploring outlier detection, influence diagnostics, and robust regression techniques. Students will progress from identifying anomalies using leverage and Cook's Distance to implementing robust algorithms like RANSAC and M-estimators.
A graduate-level sequence focused on the theoretical derivation of OLS estimators and the rigorous diagnostic procedures required to validate bivariate linear models. Students progress from matrix algebra proofs to advanced residual analysis, transformations, and cross-validation techniques.
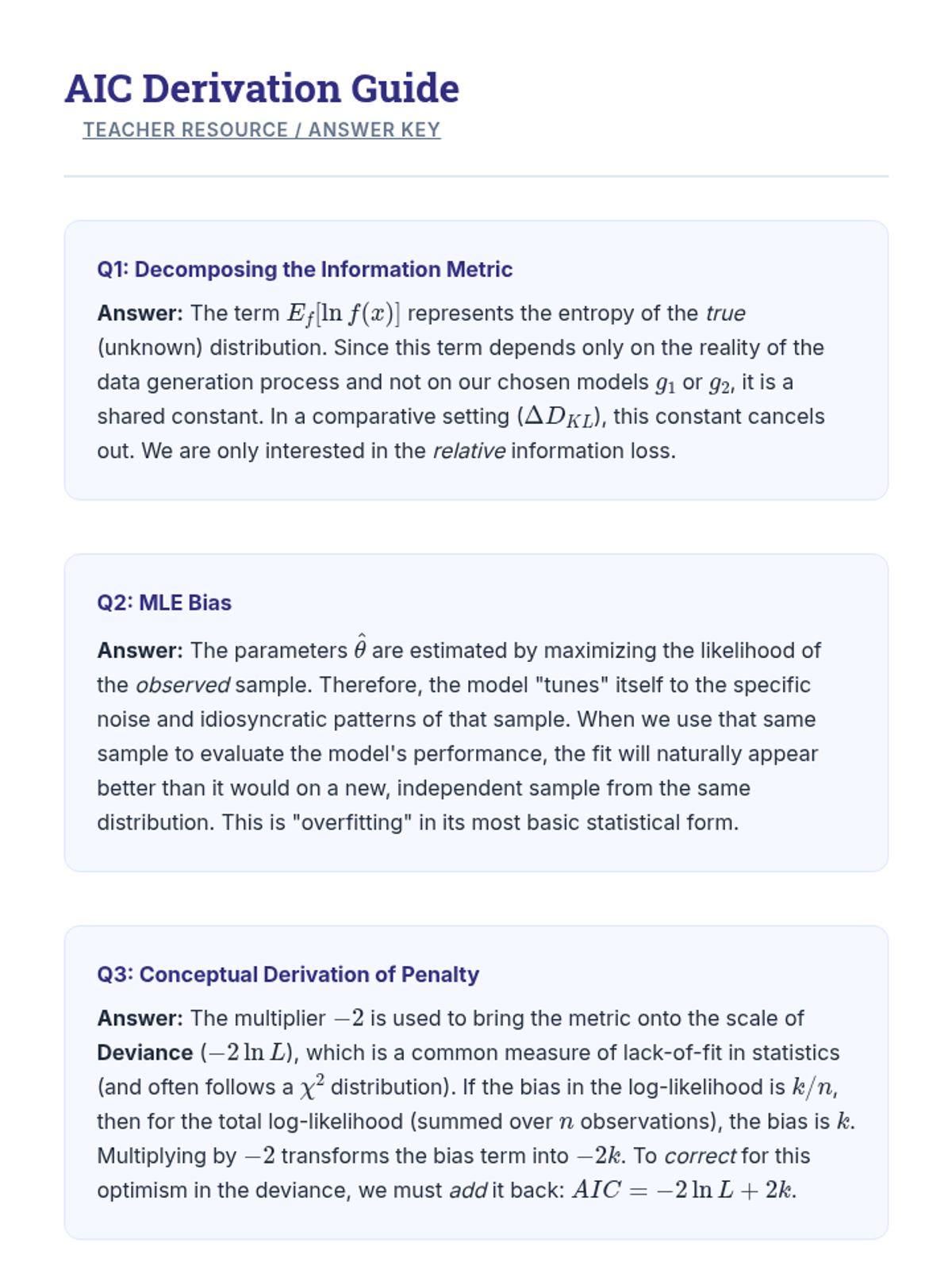
A graduate-level exploration of probabilistic model selection, focusing on AIC and BIC, their information-theoretic foundations, and practical application in statistical modeling.
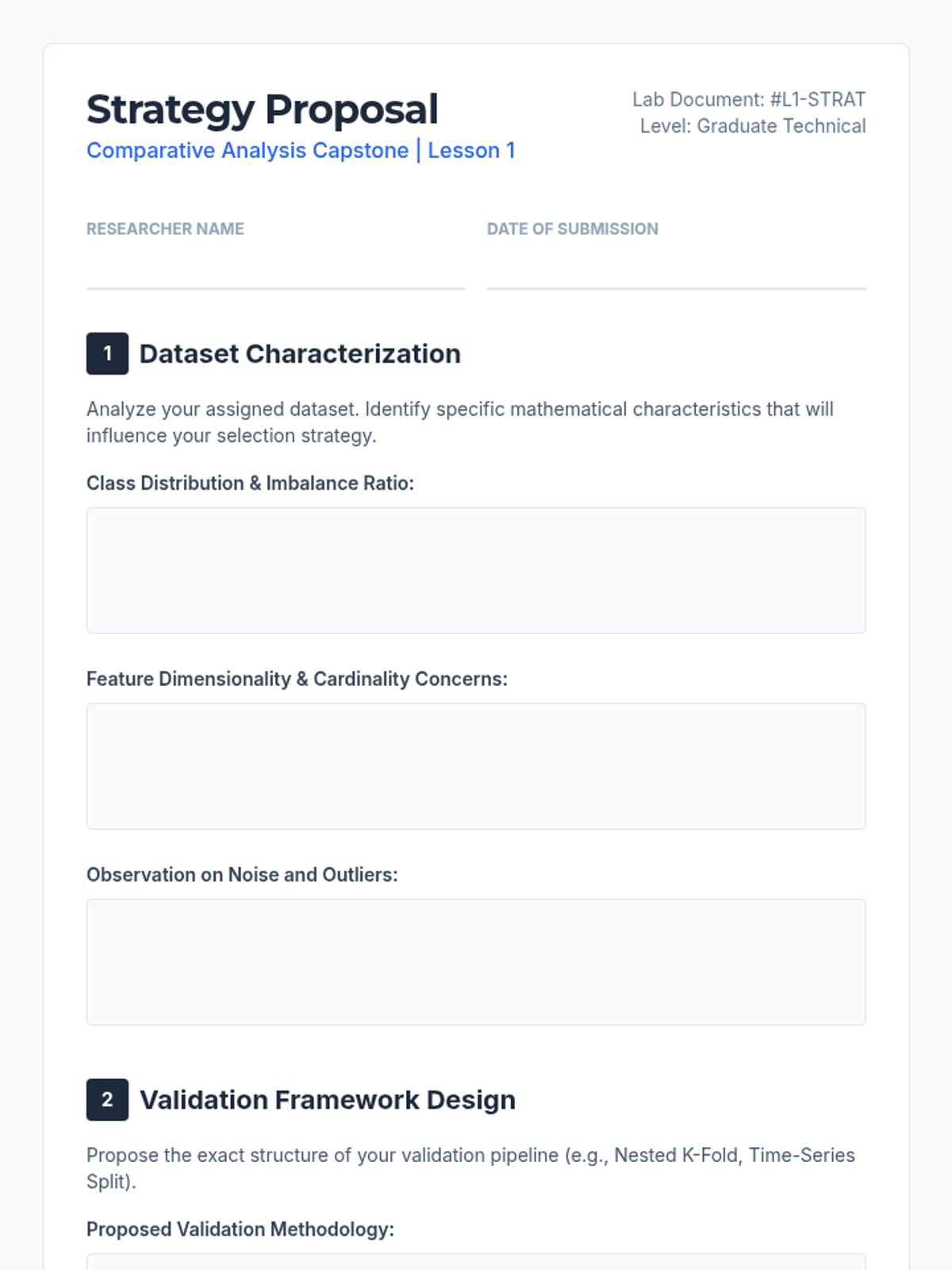
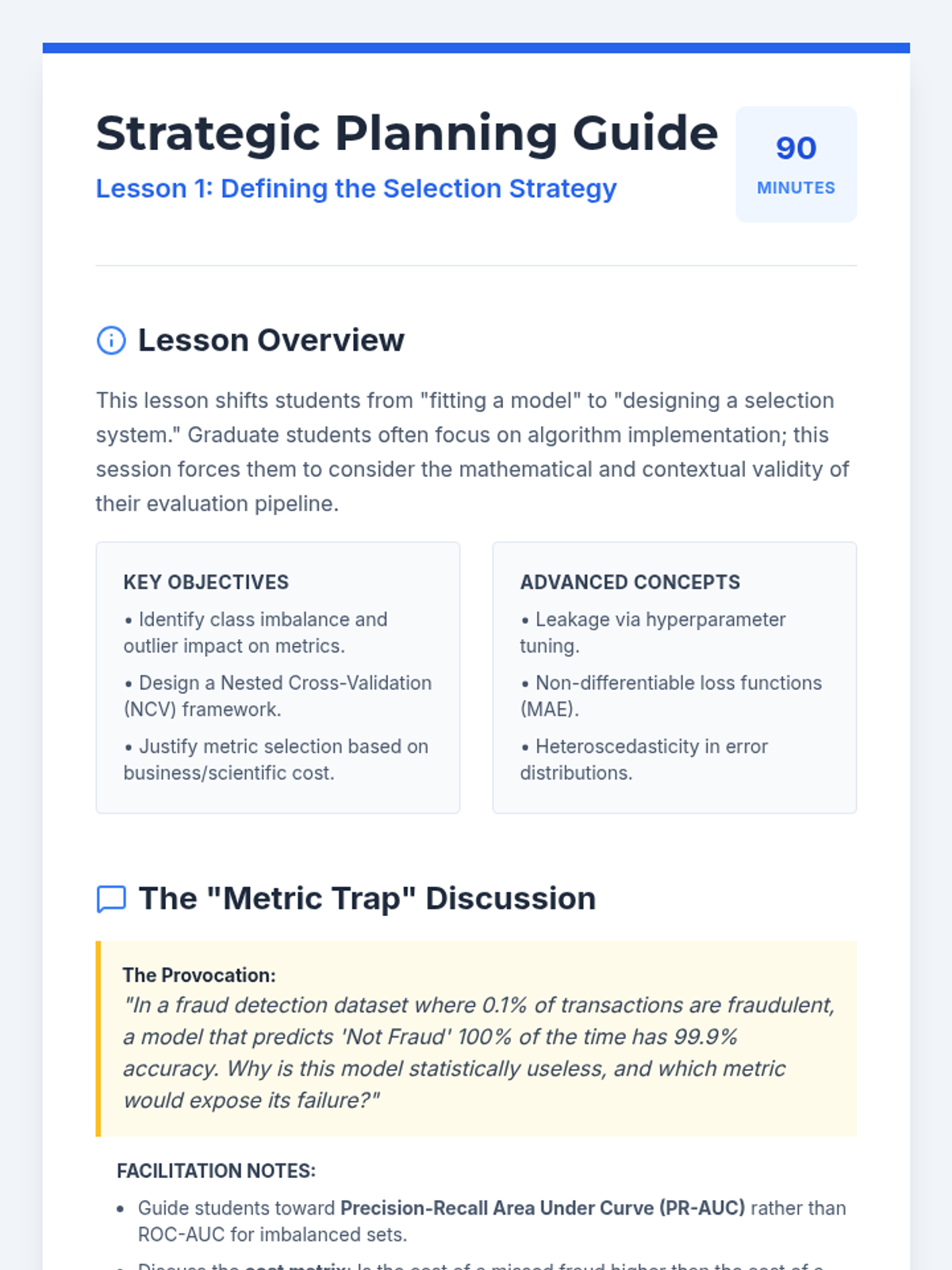
A graduate-level project-based sequence focused on the rigorous comparison and selection of mathematical models. Students progress from strategy definition and candidate generation to statistical benchmarking and stability analysis, culminating in a professional-grade technical defense.
An advanced exploration of robust statistical methods for quantifying variability, focusing on the mathematical foundations of L1 vs L2 norms, breakdown points, and efficiency trade-offs in the presence of outliers.
This graduate-level sequence bridges univariate statistics and multivariate geometry, exploring how variability manifests in high-dimensional spaces through covariance matrices, generalized variance, and principal component analysis.
A comprehensive sequence on stochastic processes, stationarity, autocorrelation, and ergodicity, designed for undergraduate statistics and engineering students. The sequence moves from basic definitions of ensemble averages to the complex relationship between time and statistical averages.
An advanced graduate-level sequence exploring the mathematical foundations of model selection, including bias-variance decomposition, information criteria (AIC/BIC), resampling methods, and high-dimensional diagnostic strategies.
This sequence guides undergraduate students through model comparison and selection, covering the bias-variance tradeoff, cross-validation methods, and information criteria (AIC/BIC). Students will learn to balance model complexity with generalization ability to select the most robust models for prediction and inference.
This graduate-level sequence bridges the gap between statistical association and causal inference. Students explore pitfalls like Simpson's Paradox and collider bias while learning to use Directed Acyclic Graphs (DAGs) and Instrumental Variables to isolate causal mechanisms in bivariate data.
A graduate-level exploration of non-linear bivariate analysis, moving from the limitations of linear correlation to rank-based methods, local regression, and information-theoretic metrics. Students develop the skills to quantify complex dependencies in biological, financial, and environmental systems where standard assumptions fail.
A graduate-level sequence exploring the gradient vector as the foundational tool for modern optimization. Students move from the geometric interpretation of multivariate derivatives to the implementation of stochastic algorithms used in machine learning.
This sequence bridges the gap between discrete mathematics and quantitative finance, focusing on the application of geometric series to asset valuation, loan amortization, and risk management. Graduate students will develop the mathematical foundations for pricing complex financial instruments and understanding market dynamics.
A graduate-level exploration of expected value through the lens of measure theory, covering Lebesgue integration, fundamental inequalities, convergence theorems, and conditional expectation using Sigma-algebras.
An advanced graduate-level exploration of stochastic processes, covering discrete and continuous-time Markov chains, Poisson processes, and queueing theory. The sequence bridges theoretical rigor with computational application through simulations and real-world modeling.
An advanced graduate-level sequence exploring the mathematical foundations and computational applications of stochastic processes, from discrete-time Markov chains to Monte Carlo simulations.
A graduate-level sequence exploring continuous-time stochastic processes through the lens of computational simulation. Students transition from discrete to continuous time models, focusing on Poisson processes, CTMCs, and queuing theory with a strong emphasis on empirical validation and theoretical rigor.
A graduate-level exploration of the mathematical foundations of discrete-time Markov chains, focusing on state classification, limiting behavior, and time reversibility. This sequence emphasizes formal derivation, proofs, and the application of linear algebra to stochastic systems.
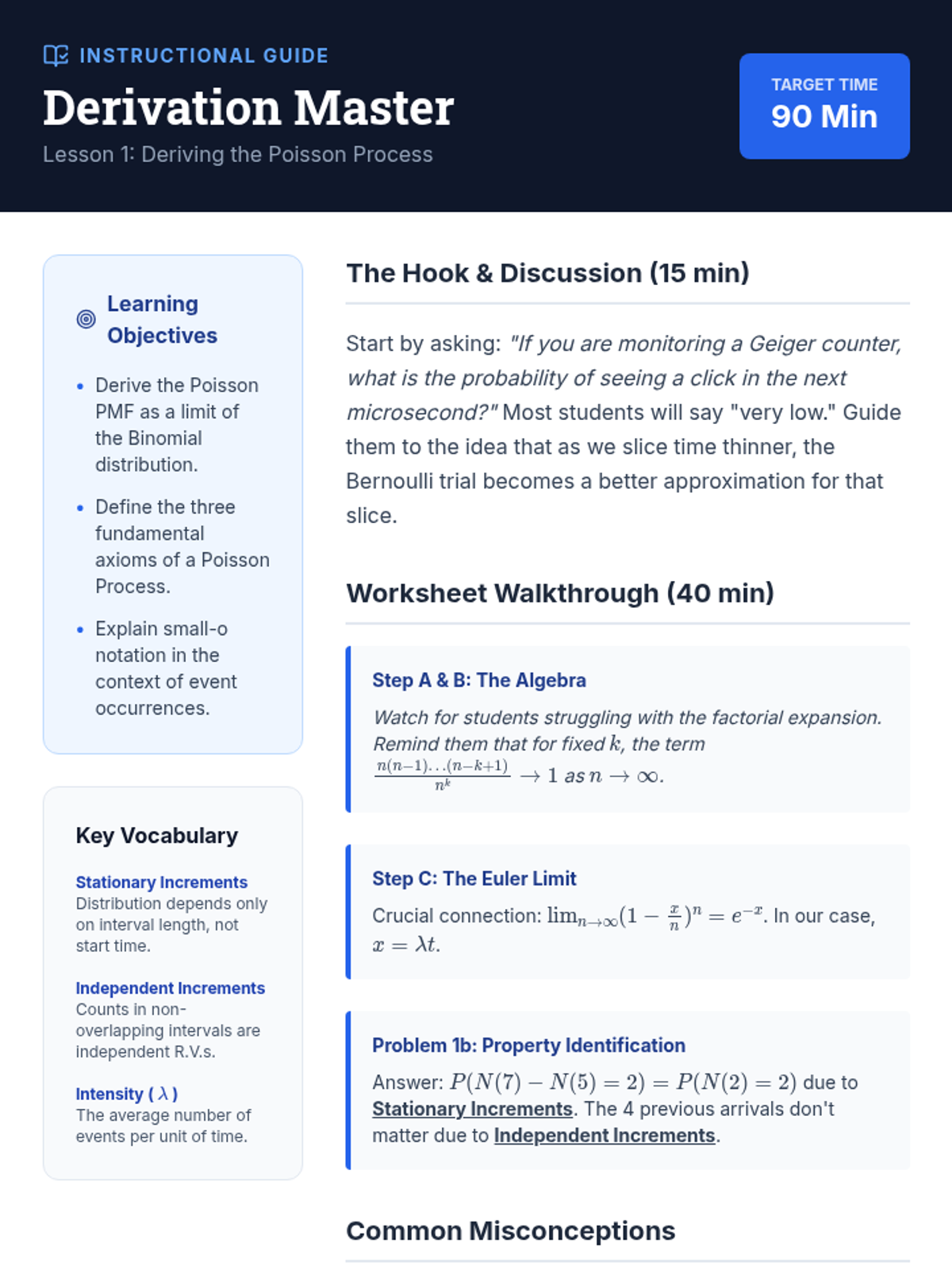
An undergraduate-level sequence exploring Poisson processes as continuous-time counting models, covering derivations, inter-arrival times, superposition, order statistics, and non-homogeneous variations.
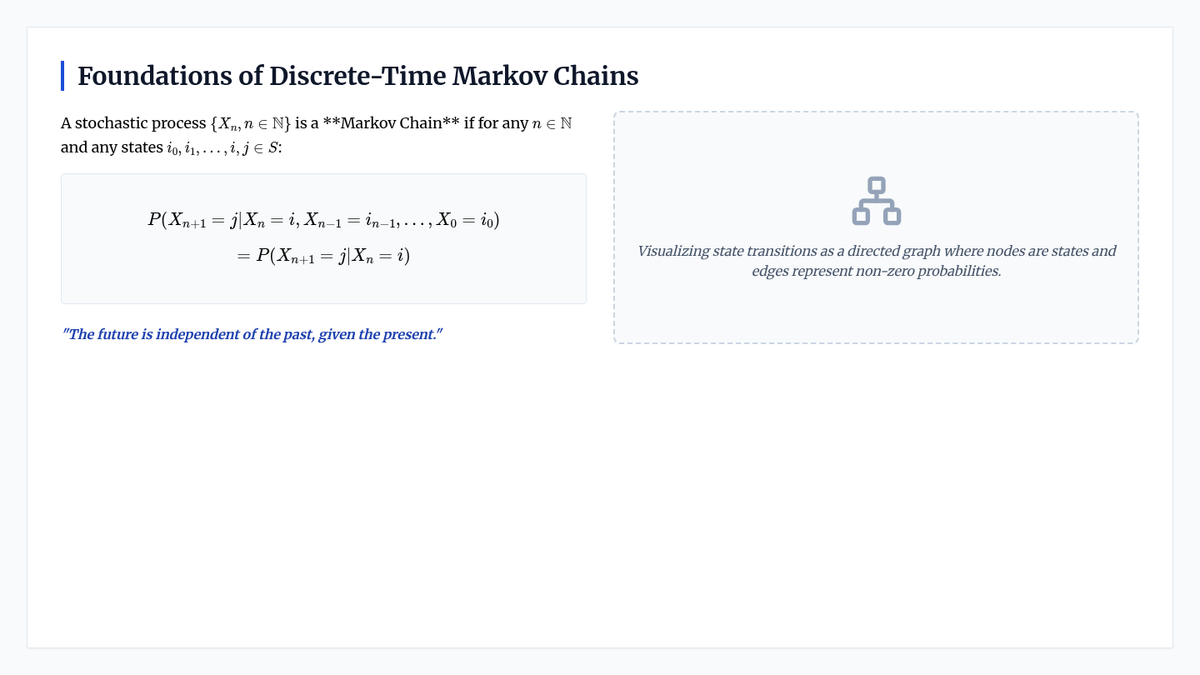
An undergraduate-level introduction to Discrete-Time Markov Chains, covering state classification, transition matrices, n-step probabilities, and stationary distributions. Students will apply linear algebra and probability theory to model stochastic systems and solve classic problems like Gambler's Ruin.
An undergraduate-level exploration of compound event probabilities through the lens of games of chance, focusing on combinatorics, non-replacement scenarios, and expected value.
A comprehensive module for undergraduate students focusing on visual methods for solving compound probability problems. The sequence progresses from basic tree diagrams and contingency tables to the Law of Total Probability and Bayesian reasoning in medical diagnostics, concluding with decision analysis simulations.
This graduate-level sequence focuses on the quantitative side of logical fallacies, exploring how data, statistics, and visualizations are manipulated in professional and academic discourse. Students will develop advanced skills in Bayesian reasoning, data auditing, and visual literacy to identify and correct misleading arguments.