Mapping relationships through notation, algebraic representations, and growth rate comparisons. Equips learners to transform functions, model contextual data, and solve exponential equations.
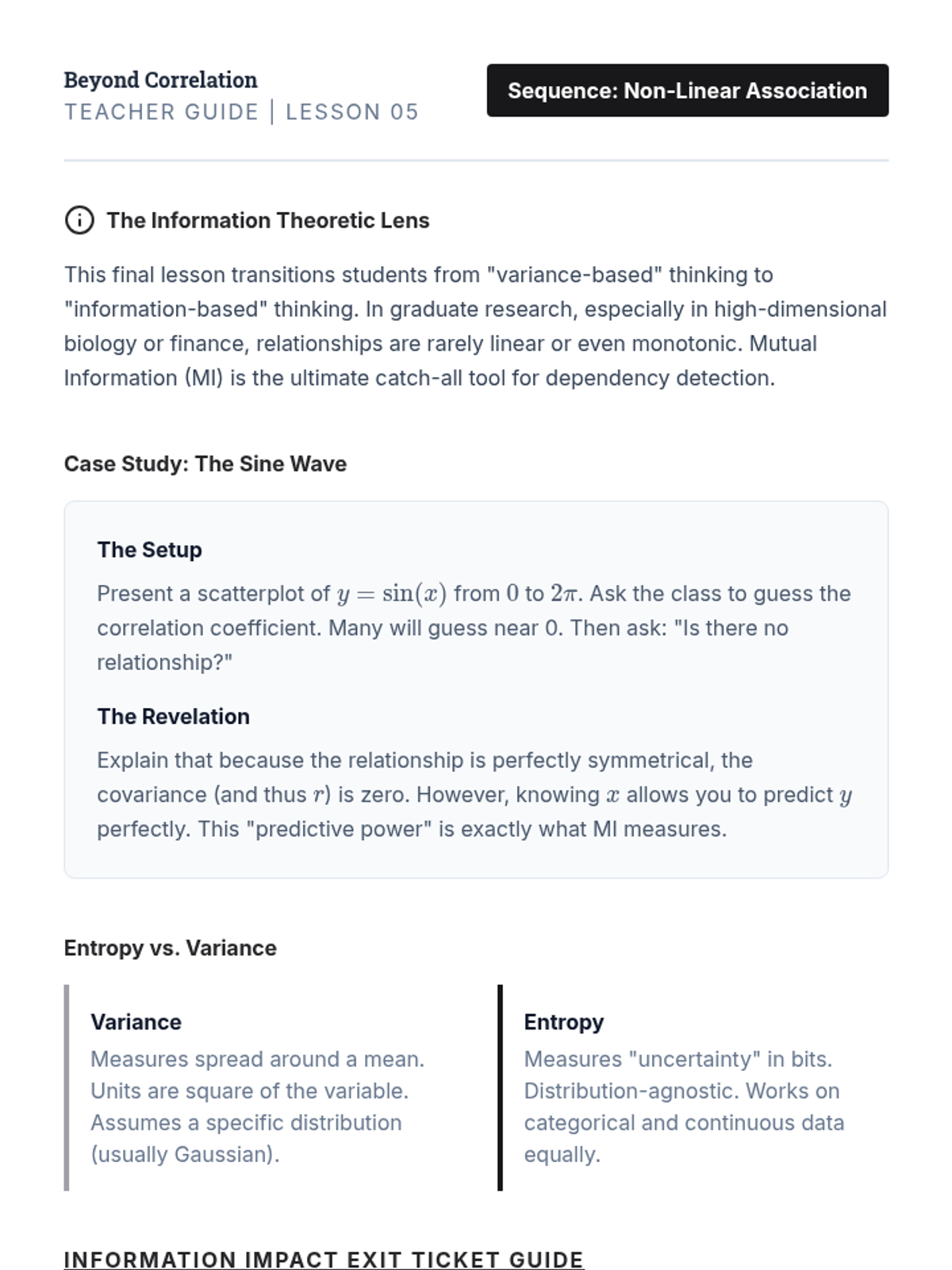
The sequence concludes with Information Theory metrics, using Mutual Information to detect non-monotonic, complex associations that correlation coefficients miss.
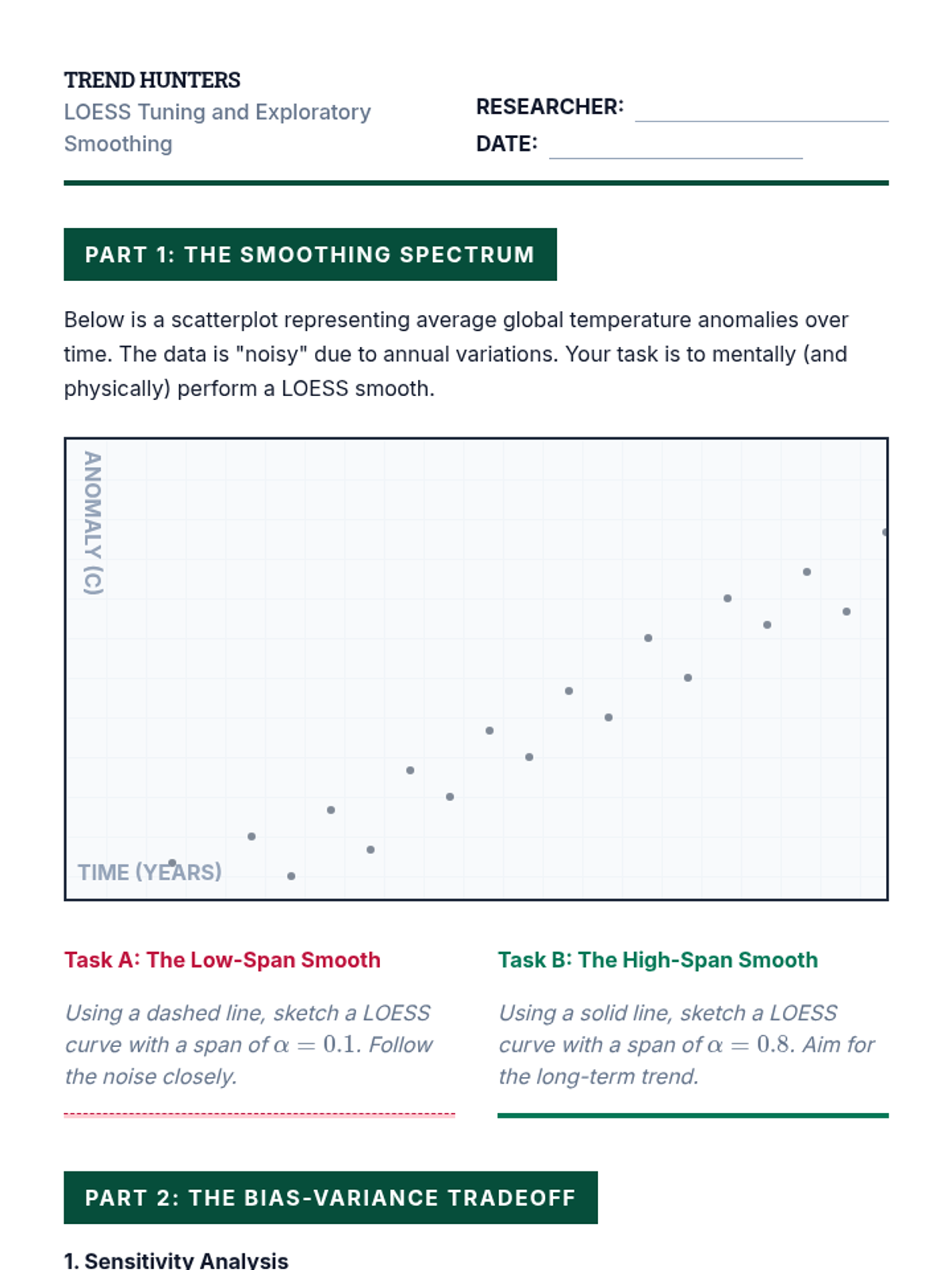
This lesson focuses on locally weighted scatterplot smoothing (LOESS) to visualize trends without pre-defined parametric functions, exploring bandwidth selection and smoothing.
Students explore modeling curvature using polynomial terms and splines, while addressing the bias-variance tradeoff and the risks of overfitting.
This lesson introduces Spearman’s rho and Kendall’s tau for assessing monotonic relationships in ordinal and non-normal continuous data.
Students analyze Anscombe's Quartet and other pathological datasets to demonstrate where Pearson’s r fails, focusing on the distinction between linearity and general association.
The culmination of the project where students synthesize their findings into a technical report and defend their model choice based on performance, trade-offs, and generalization expectations.
Students explore model sensitivity and selection bias through stability analysis and data perturbation to ensure the chosen model generalizes robustly across varying data distributions.
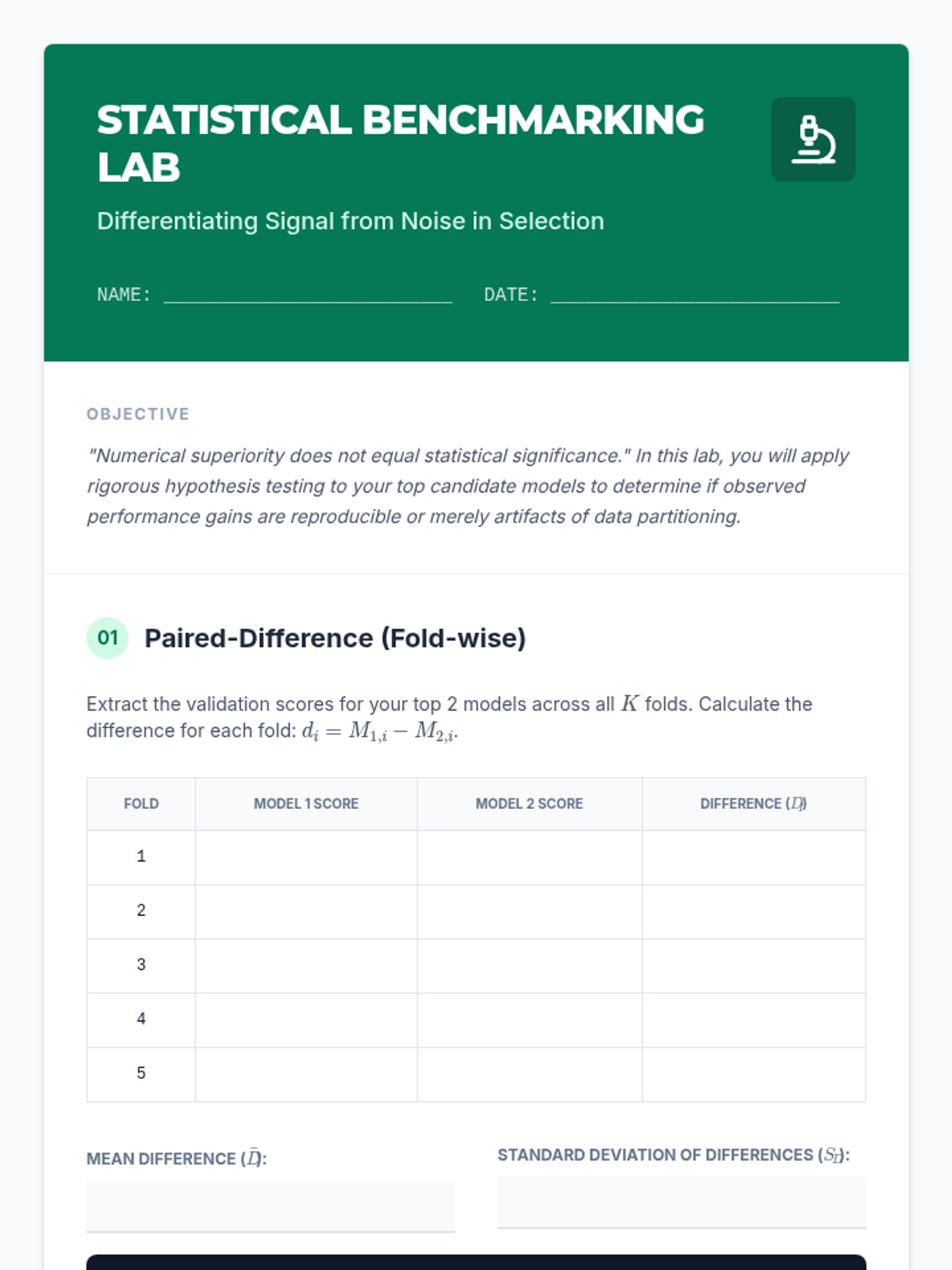
Focuses on the statistical rigor of model comparison, utilizing hypothesis testing and confidence intervals to differentiate between genuine performance signals and random fluctuations.
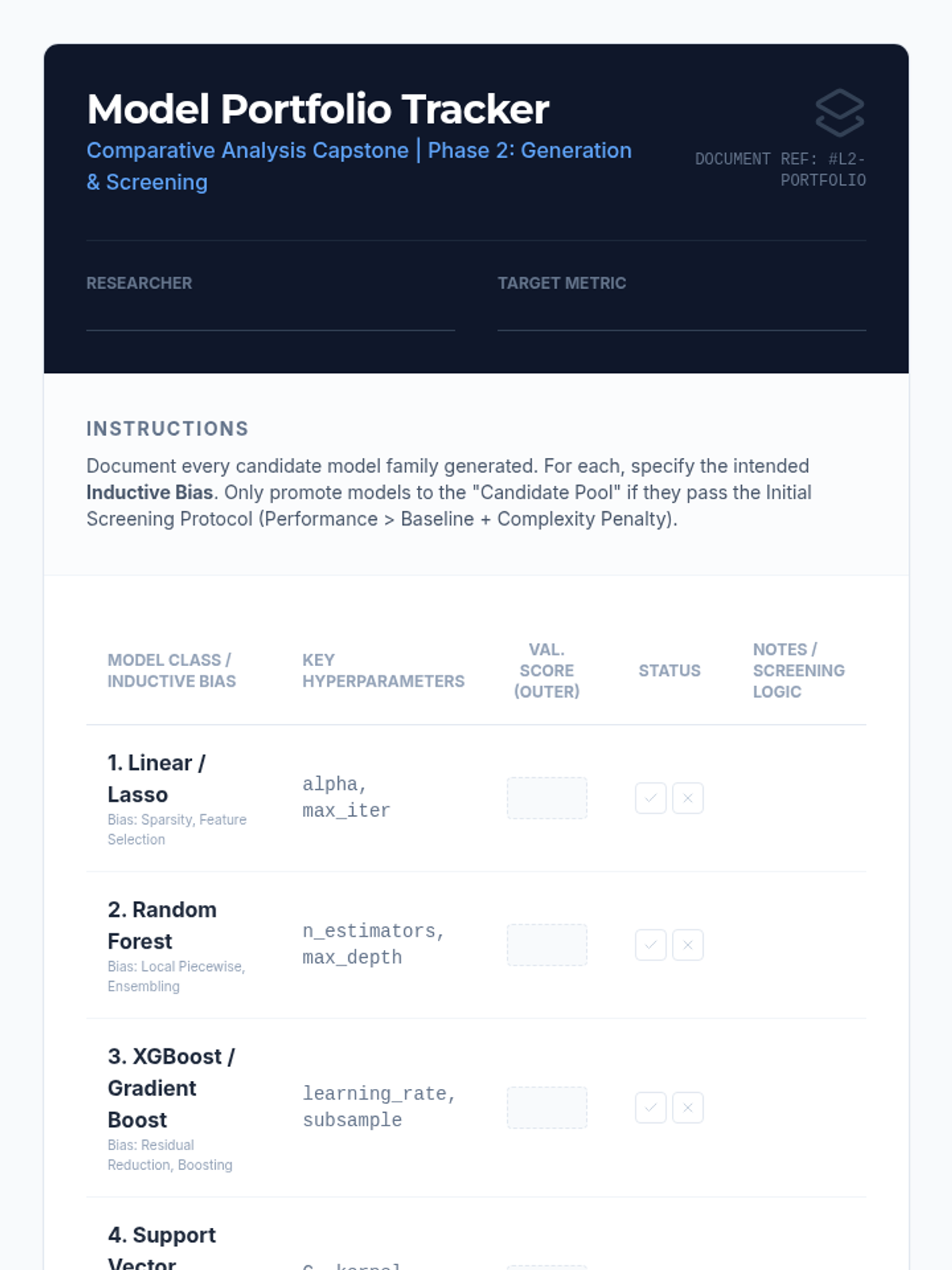
Students develop a diverse portfolio of candidate models using various mathematical frameworks (linear, tree-based, regularized) and implement screening protocols to filter low-performing architectures.
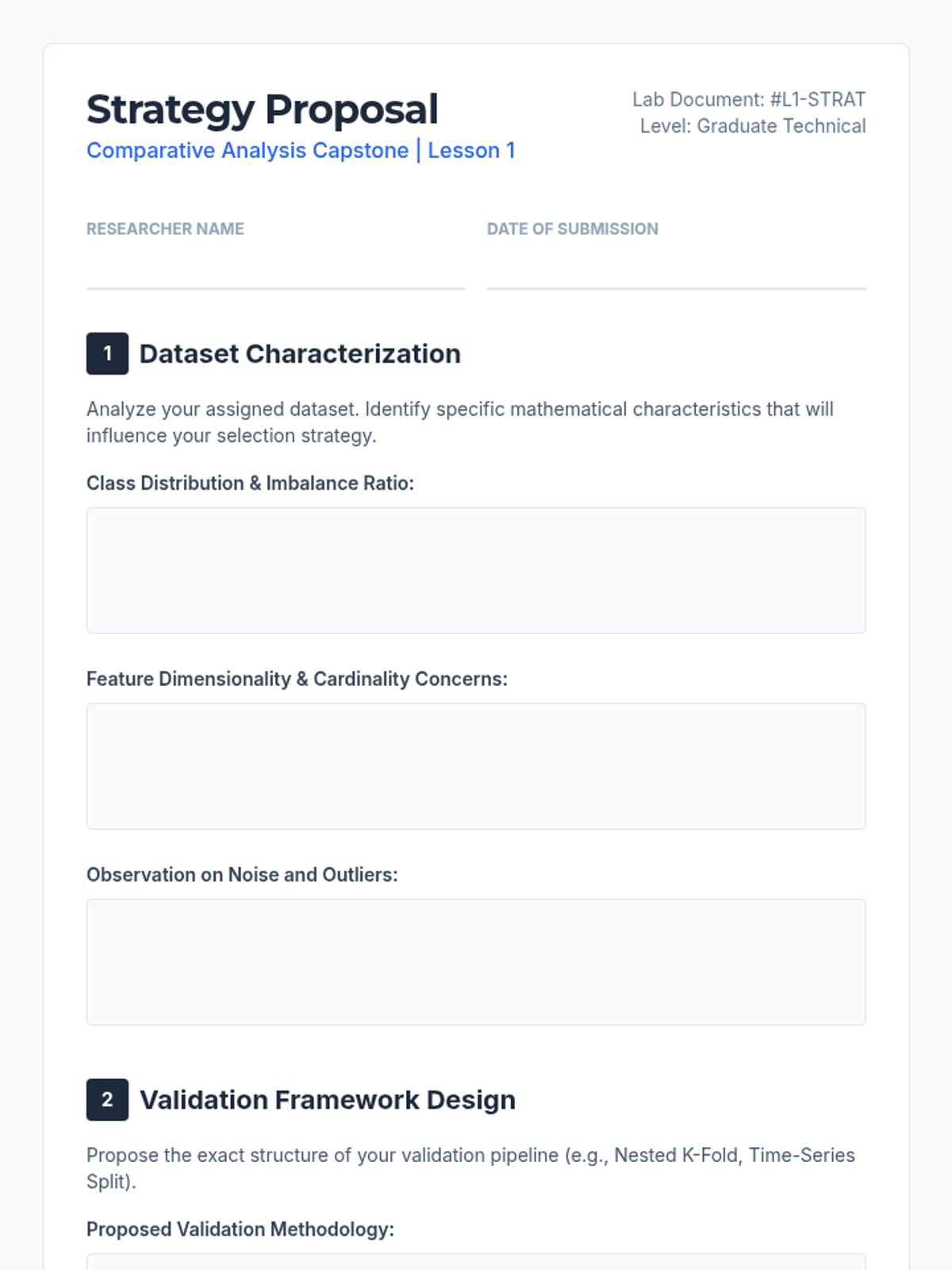
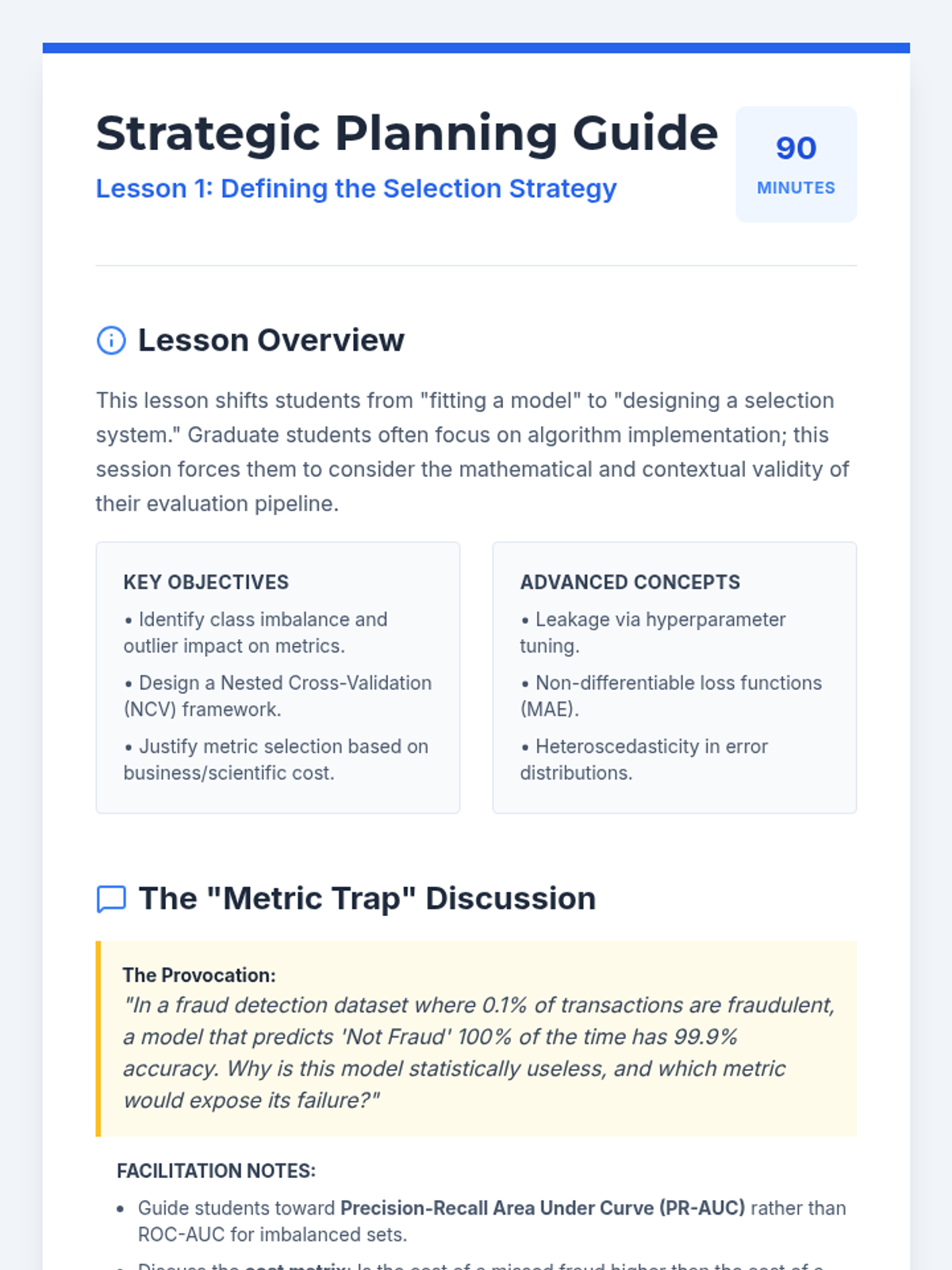
Students analyze complex datasets to design robust validation frameworks and select context-appropriate error metrics. The focus is on preventing overfitting and ensuring metric reliability in the presence of noise and class imbalance.
Final synthesis of model selection criteria to defend a chosen model for a complex dataset.
Comparative analysis of model selection metrics in high-dimensional settings where p is large relative to n.
Computational implementation and analysis of cross-validation architectures for out-of-sample error estimation.
Theoretical exploration of AIC and BIC, focusing on Kullback-Leibler divergence and Bayesian approximations.
Mathematical derivation of the bias-variance tradeoff and its implications for model complexity using squared error loss.
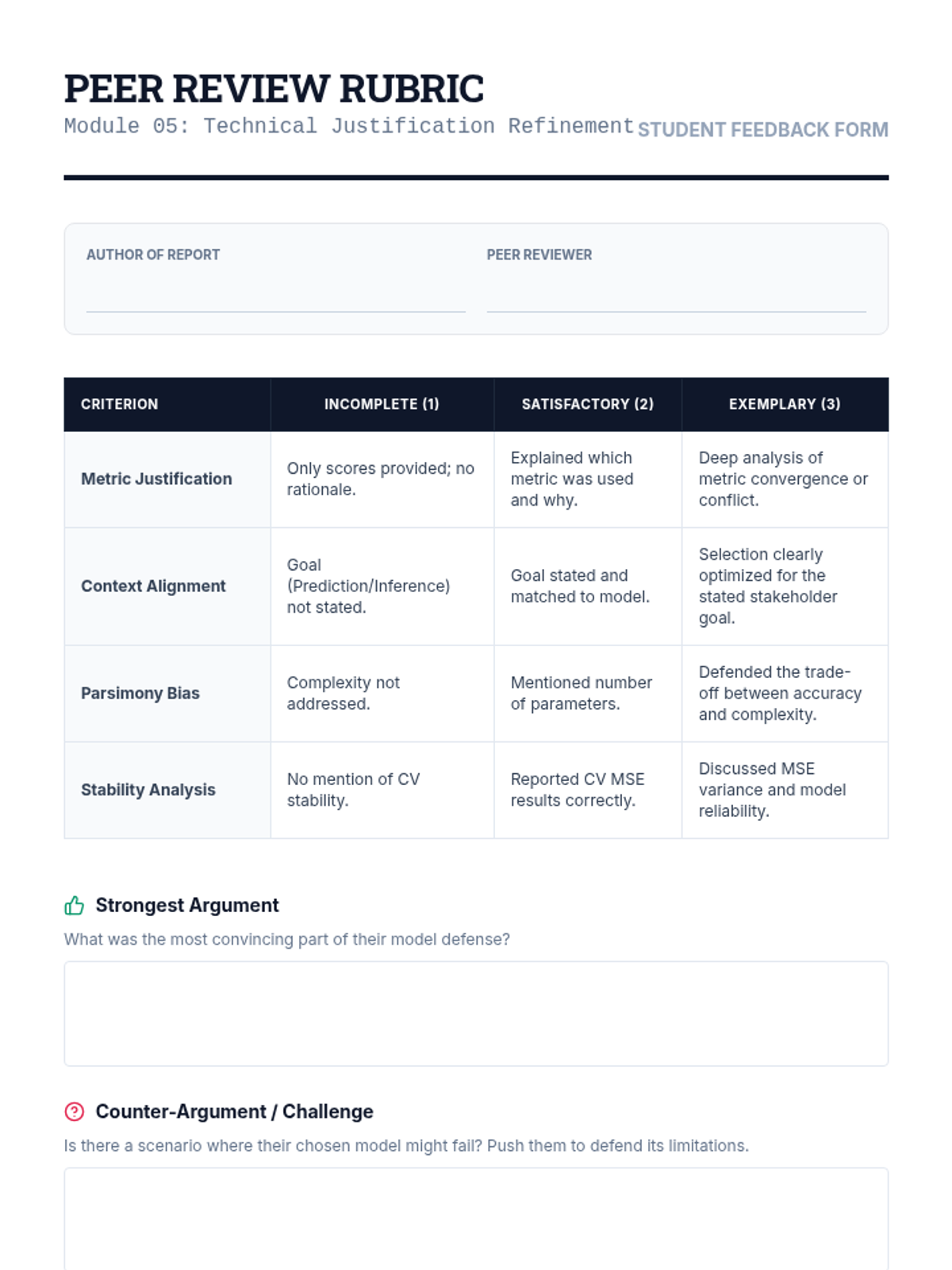
Synthesize the sequence by selecting and justifying a final model for a real-world dataset. Students must defend their choice based on predictive accuracy, parsimony, and interpretability in a technical report format.
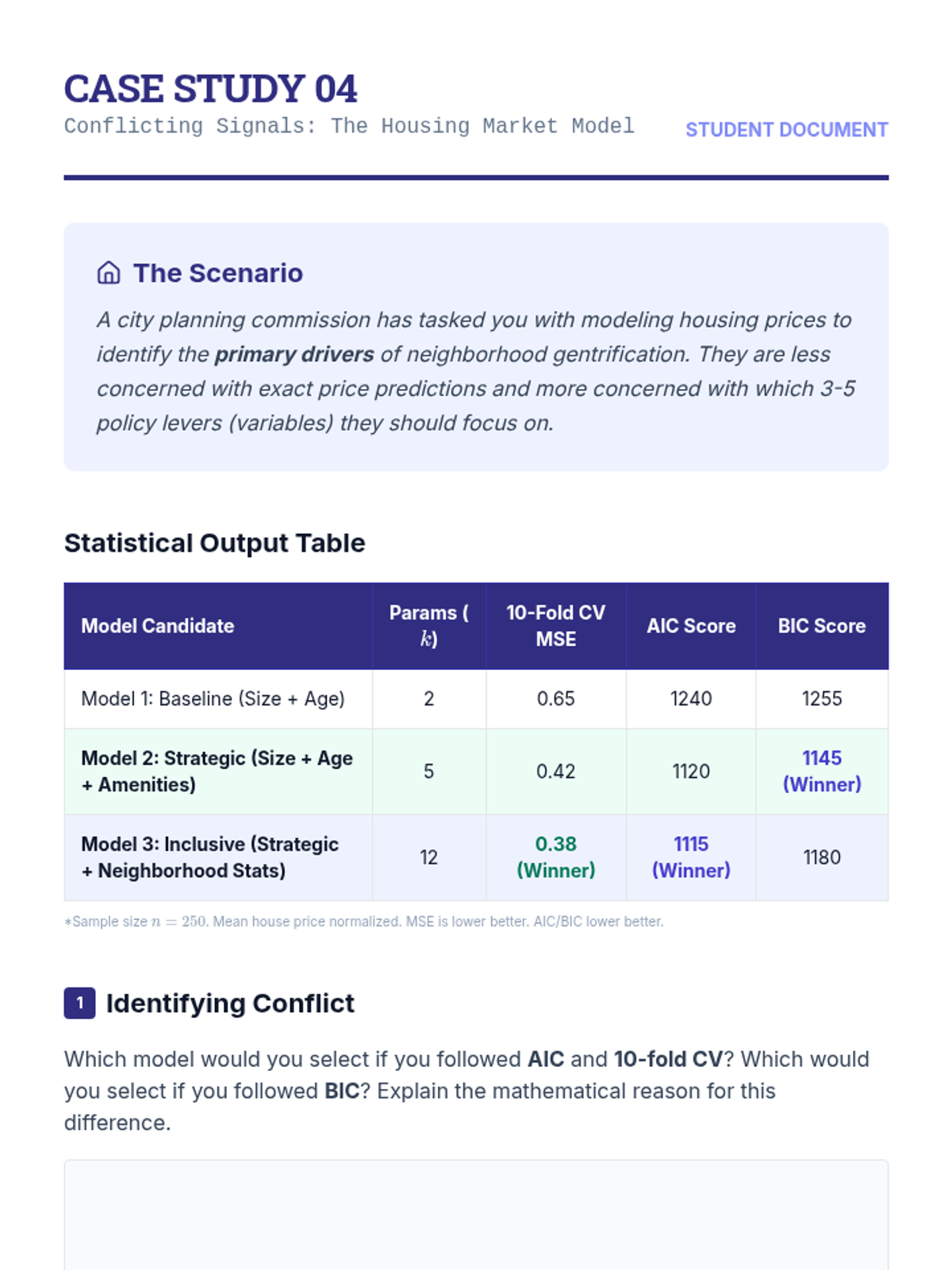
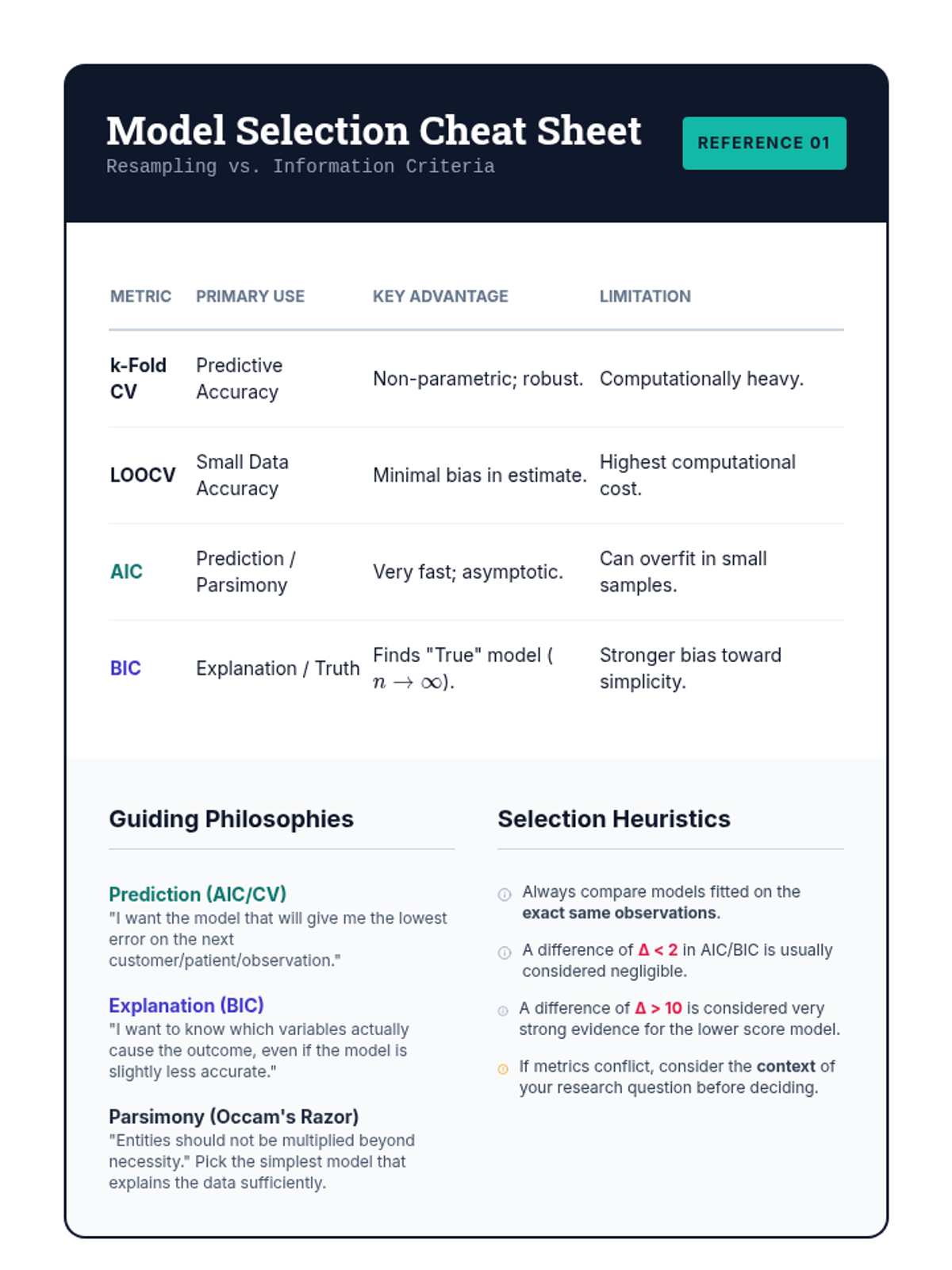
Analyze scenarios where different selection metrics provide conflicting results. Students reconcile cross-validation and information criteria outcomes by considering the specific goals of the analysis, such as prediction versus explanation.
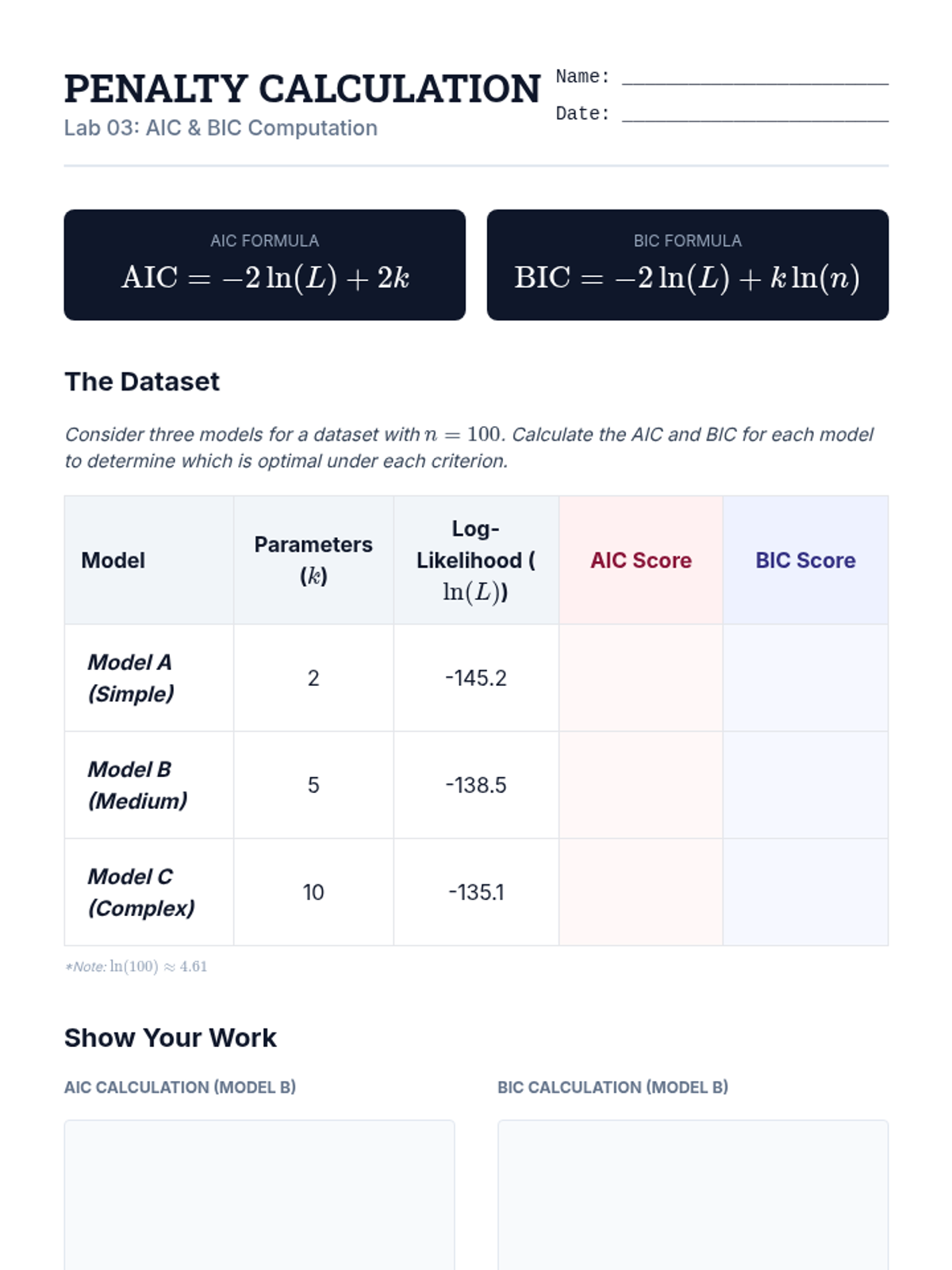
Dive into the theoretical foundations of information criteria. Students calculate and compare AIC and BIC, understanding how these metrics penalize model complexity and the implications of using different penalty terms in model selection.
Learn rigorous resampling methods to estimate out-of-sample performance. Students compare k-fold cross-validation and Leave-One-Out Cross-Validation (LOOCV), analyzing their computational costs and the reliability of their error estimates.
Explore the core concepts of underfitting and overfitting through polynomial regression simulations. Students visualize how increasing model complexity reduces bias but increases variance, leading to a divergence between training and testing error.